DI: Mark Reiten, Vice President, Licensing Business Unit, Silicon Storage Technology (SST), una consociata interamente controllata da Microchip Technology
Machine learning e Deep Learning sono già parte integrante della nostra vita. Le applicazioni di Artificial Intelligence (AI) tramite Natural Language Processing (NLP), classificazione delle immagini e il rilevamento degli oggetti sono profondamente integrate in molti dei dispositivi che quotidianamente utilizziamo. La maggior parte delle applicazioni di AI sono servite tramite motori basati su cloud che funzionano bene per l’uso che ne viene fatto, come per esempio ottenere la previsione di parole durante la digitazione di un e-mail di risposta in Gmail.
Per quanto tutti noi godiamo dei vantaggi di queste applicazioni di AI, questo approccio introduce problemi di privacy, dissipazione di potenza, latenza e costi. Queste sfide possono essere risolte nel caso esista un motore locale di elaborazione in grado di eseguire calcoli parziali o completi (inferenza) all’origine dei dati stessi. Questo è stato difficile da realizzare con le tradizionali implementazioni di reti neurali digitali, in cui la memoria diventa un collo di bottiglia assetato di energia. Il problema può essere risolto con memoria multilivello e l’uso di un metodo di calcolo analogico in-memory che, insieme, consentono ai motori di elaborazione di soddisfare requisiti di un consumo molto più basso, nell’ordine di grandezza da milliwatt (mW) a microwatt (uW), per eseguire l’inferenza AI sull’Edge di rete.
Le Sfide del Cloud Computing
Quando le applicazioni di intelligenza artificiale vengono servite da motori basati su Cloud, l’utente (volente o nolente) deve caricare alcuni dati sul Cloud in cui i motori di elaborazione elaborano i dati, forniscono previsioni, e inviano le previsioni in downstream all’utente per il loro utilizzo. Le sfide associate a questo processo sono descritte di seguito:

Figura 1: Trasferimento dati tra Edge e Cloud
- Problemi di privacy e sicurezza: con dispositivi always-on e always-aware, c’è il timore che i dati personali (e/o informazioni riservate) vengano utilizzati in modo improprio, durante i caricamenti o durante la loro conservazione nei data center.
- Dissipazione di potenza non necessaria: se ogni bit di dati va nel Cloud, consuma energia attraverso hardware, radio, trasmissione e potenzialmente anche in calcoli indesiderati nel Cloud.
- Latenza per inferenze in batch di piccole dimensioni: a volte può essere necessario un secondo o più per ottenere una risposta da un sistema basato su cloud se i dati provengono dall’Edge. Per i sensi umani, qualsiasi cosa che superi i 100 millisecondi (ms) di latenza viene percepita come evidente e può risultare fastidiosa.
- L’economia dei dati deve avere un senso: i sensori sono ovunque e sono molto convenienti; tuttavia, producono una quantità elevata di dati. Non è economico caricare ogni bit di questi dati nel Cloud e farli elaborare.
Per risolvere queste sfide utilizzando un motore di elaborazione locale, il modello di rete neurale che eseguirà le operazioni di inferenza deve prima essere preparato con un determinato set di dati per il caso d’uso desiderato. In genere, ciò richiede elevate risorse di calcolo (e memoria) e operazioni aritmetiche in virgola mobile. Di conseguenza, la parte di preparazione di una soluzione di machine learning deve ancora essere eseguita su cloud pubblici o privati (o FPGA farm, CPU, GPU locali) con un set di dati per generare un modello di rete neurale ottimale. Una volta che il modello di rete neurale è pronto, il modello può essere ulteriormente ottimizzato per un hardware locale con un piccolo motore di calcolo perché il modello di rete neurale non necessita di retropropagazione per l’operazione di inferenza. Un motore di inferenza generalmente necessita di un mare di motori Multiply-Accumulate (MAC), seguito da un livello di attivazione come una rectified linear unit (ReLU), sigmoide o tanh a seconda della complessità del modello di rete neurale e un livello di pooling tra i layer.
La maggior parte dei modelli di rete neurale richiede una grande quantità di operazioni MAC. Ad esempio, anche un modello relativamente piccolo “1.0 MobileNet 224” ha 4,2 milioni di parametri (weights) e richiede 569 milioni di operazioni MAC per eseguire un’inferenza. Poiché la maggior parte dei modelli è dominata dalle operazioni MAC, l’attenzione qui sarà su questa parte del calcolo dell’apprendimento automatico e sull’esplorazione dell’opportunità di creare una soluzione migliore. Una semplice rete two-layer completamente connessa è illustrata di seguito nella Figura 2.
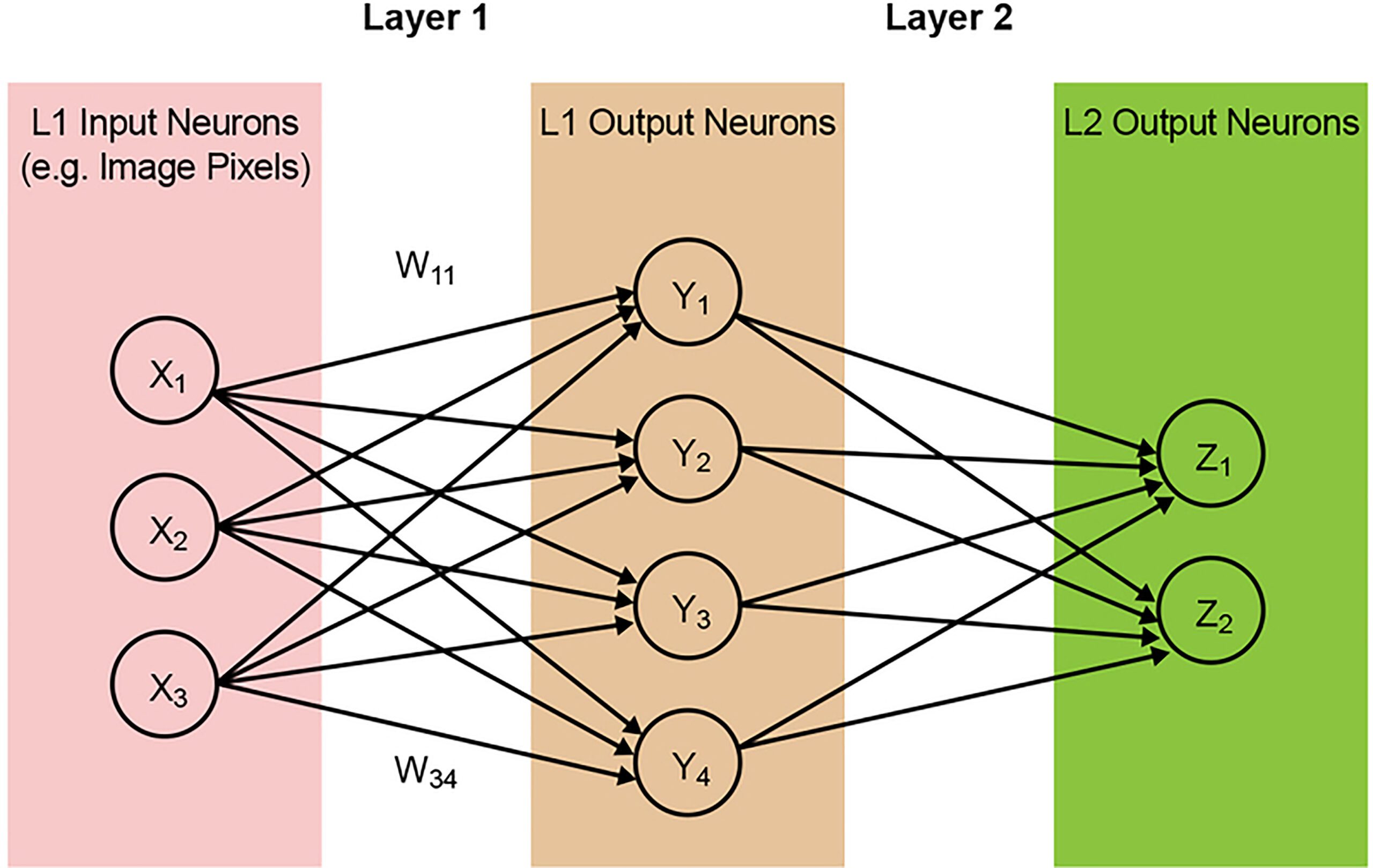
Figura 2: Rete neurale completamente connessa Two Layer
I neuroni di input (dati) vengono elaborati con il primo layer di weights. I neuroni in uscita dai primi strati vengono quindi elaborati con il second layer di weights e forniscono previsioni (diciamo, se il modello è stato in grado di trovare una faccia di gatto in una determinata immagine). Questi modelli di rete neurale utilizzano il “prodotto scalare” per il calcolo di ogni neurone in ogni layer, illustrato dalla seguente equazione: (omettendo il termine ‘bias’ nell’equazione a scopo di semplificazione)
[boris]
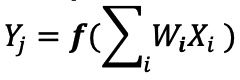
La Memoria, Collo di Bottiglia dell’Elaborazione Digitale
In un’implementazione di rete neurale digitale, weights e dati di input sono memorizzati in una DRAM/SRAM. I weights e i dati di input devono essere spostati accanto ad un motore MAC per l’inferenza. Come da diagramma seguente, con questo approccio la maggior parte della potenza viene dissipata nel recupero dei parametri del modello e dei dati di input nell’ALU in cui si svolge l’effettiva operazione MAC. Per mettere le cose in una prospettiva di calcolo energetico, una tipica operazione MAC che utilizza porte logiche digitali consuma ~ 250 fJ di energia, ma l’energia dissipata durante il trasferimento dei dati è più di due ordini di grandezza superiore rispetto al calcolo stesso e rientra nell’intervallo tra 50 Pico Jules ( pJ) e 100 pJ (Figura 3). A dire il vero, sono disponibili molte tecniche di progettazione per ridurre al minimo il trasferimento di dati dalla memoria all’ALU; tuttavia, l’intero schema digitale è ancora limitato dall’architettura di Von Neumann. Quindi questo rappresenta una grande opportunità per ridurre lo spreco di energia. Per esempio, cosa succederebbe se l’energia utilizzata per eseguire un’operazione MAC potesse essere ridotta da ~100pJ ad una frazione di pJ?
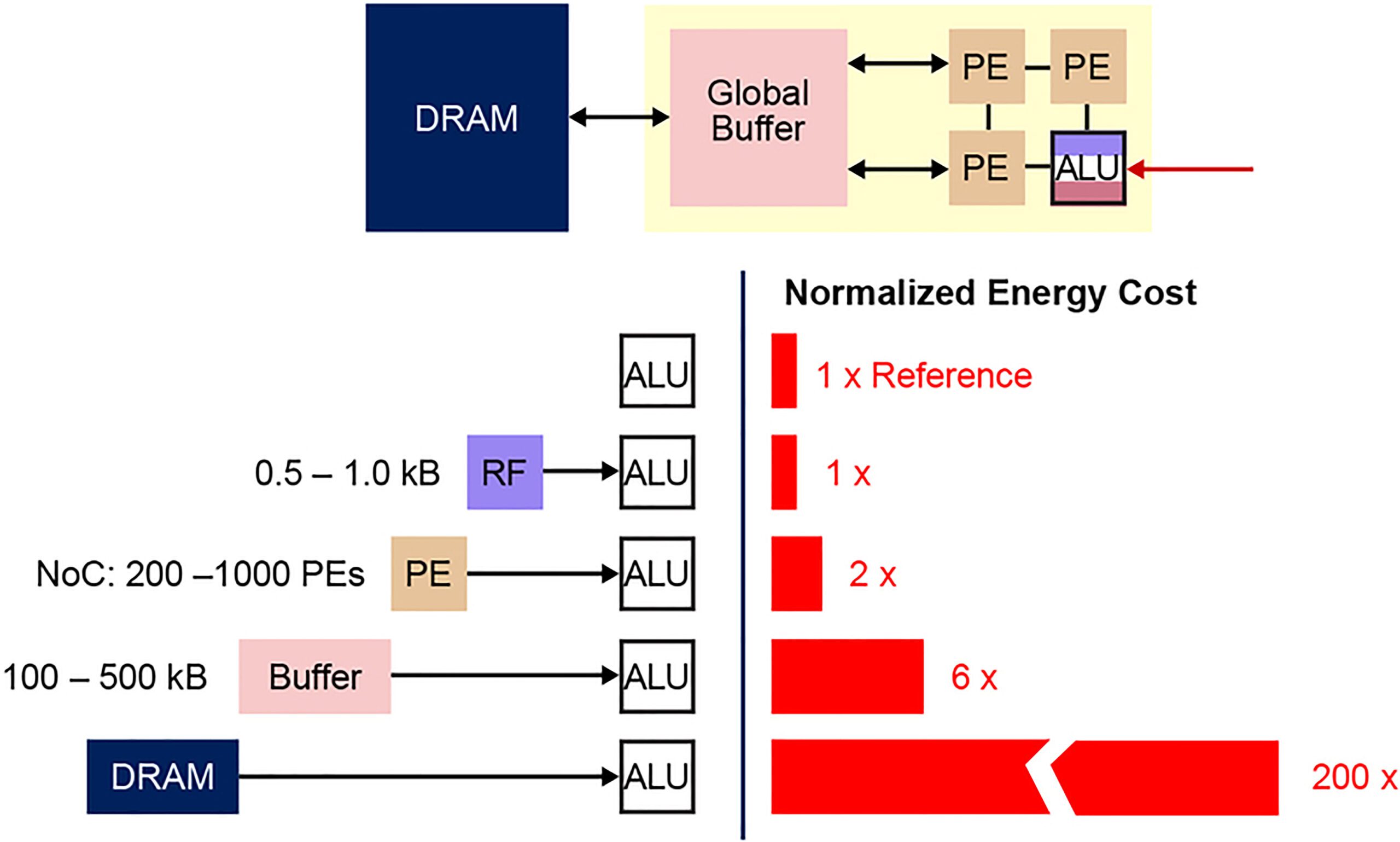
Figura 3: Collo di Bottiglia della Memoria nel Machine Learning Computation
FONTE: : Y.-H. Chen, J. Emer, and V. Sze, “Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks,” in ISCA, 2016.
Eliminazione del Collo di Bottiglia della Memoria grazie all’Analog In-Memory Computing
L’esecuzione di operazioni di inferenza sull’Edge diventa efficiente dal punto di vista energetico quando la memoria stessa può essere utilizzata per ridurre il calcolo. L’uso di un metodo di calcolo in-memory riduce al minimo la quantità di dati che devono essere spostati. Questo, a sua volta, elimina l’energia sprecata durante il trasferimento dei dati. La dissipazione di energia è ulteriormente ridotta utilizzando celle flash che possono funzionare con una dissipazione di potenza attiva ultra bassa e quasi nessuna dissipazione di energia durante la modalità standby.
Un esempio di questo approccio è la tecnologia memBrain™ di Silicon Storage Technology (SST), una società di Microchip Technology. Basata sulla tecnologia di memoria SuperFlash® di SST, diventata uno standard de facto di memoria multilivello per applicazioni di microcontroller e smartcard, la soluzione include un’architettura di elaborazione in-memory che consente di eseguire il calcolo dove sono memorizzati i weights. Ciò elimina il collo di bottiglia della memoria nel calcolo MAC poiché non vi è alcun movimento di dati per i weights: solo i dati in ingresso devono essere spostati da un sensore di input, come da una fotocamera o microfono, all’array di memoria.
Questo concetto di memoria si basa su due fondamenti: (a) la risposta della corrente elettrica analogica da un transistor si basa sulla sua tensione di soglia (Vt) e sui dati di ingresso, e (b) la legge della corrente di Kirchhoff, che afferma che la somma algebrica delle correnti in una rete di conduttori che si incontrano in un punto è zero. È anche importante comprendere la posizione di memoria fondamentale della non-volatile memory (NVM) utilizzata in questa architettura di memoria multilivello. Il diagramma seguente (Figura 4) è una sezione trasversale di due bitcell ESF3 (Embedded SuperFlash 3rd generation) con Erase Gate (EG) e Source Line (SL) condivisi. Ogni bitcell ha cinque terminali: Control Gate (CG), Work Line (WL), Erase Gate (EG), Source Line (SL) e Bitline (BL). L’operazione di cancellazione sulla bitcell viene eseguita applicando l’alta tensione su EG. L’operazione di programmazione viene eseguita applicando segnali di bias alta/bassa tensione su WL, CG, BL e SL. L’operazione di lettura viene eseguita applicando segnali di bias a bassa tensione su WL, CG, BL e SL.
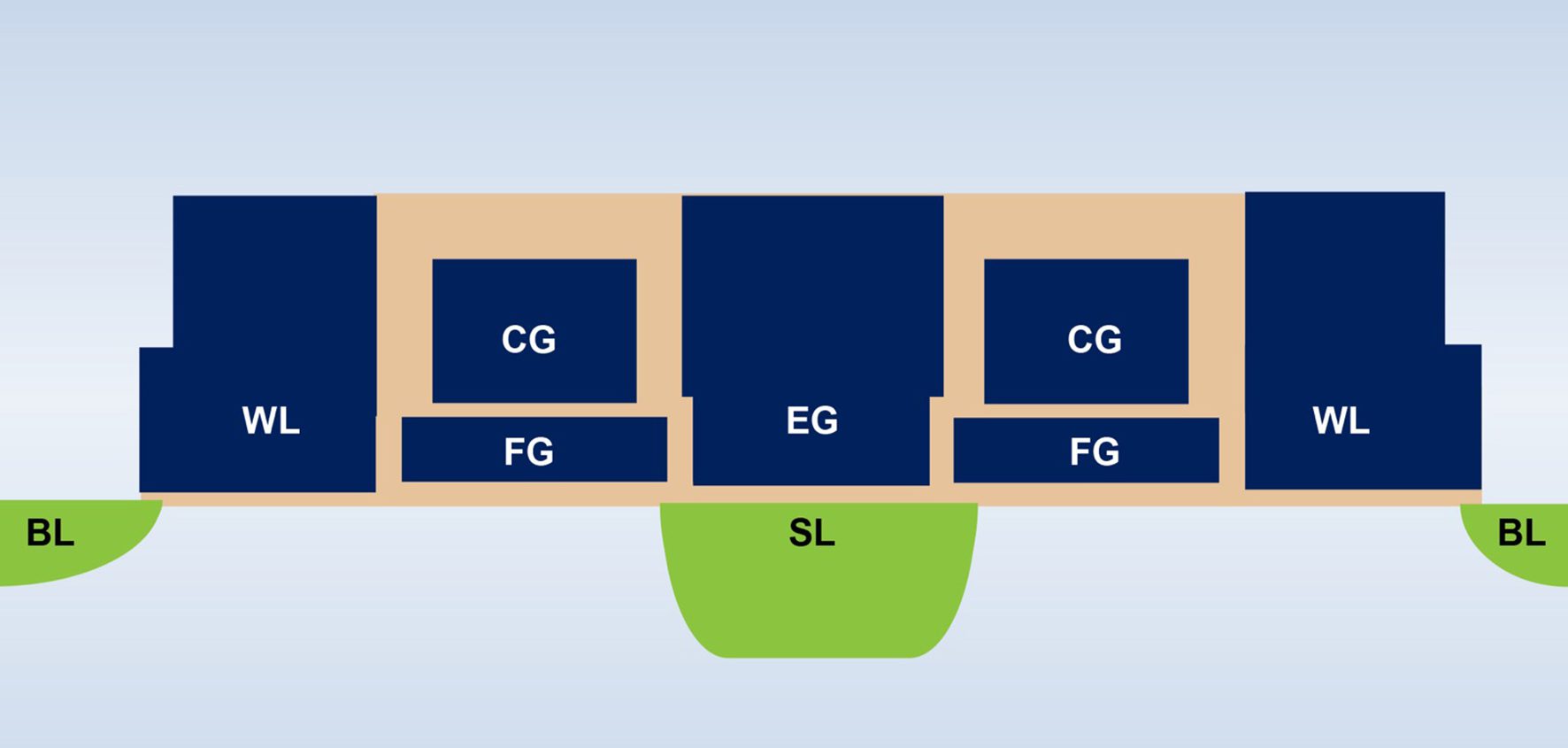
Figura 4: SuperFlash ESF3 Cell
Con questa architettura di memoria, l’utente può programmare le bitcell di memoria a vari livelli di Vt mediante un’operazione di programmazione fine. La tecnologia di memoria utilizza un algoritmo intelligente per ottimizzare il floating-gate (FG) Vt della cella di memoria per ottenere una certa risposta di corrente elettrica da una tensione di ingresso. A seconda delle esigenze dell’applicazione finale, le celle possono essere programmate in una regione operativa lineare o sottosoglia.
La figura 5 illustra la capacità di memorizzare e leggere più livelli sulla cella di memoria. Diciamo per esempio che stiamo cercando di memorizzare un valore intero, di 2 bit in una cella di memoria. Per questo scenario, dobbiamo programmare ogni cella in un array di memoria con una delle quattro possibilità di valori interi a 2 bit (00, 01, 10, 11). Le quattro curve sottostanti sono una curva IV per ciascuno dei quattro possibili stati e la risposta della corrente elettrica dalla cella dipenderebbe dalla tensione applicata su CG.
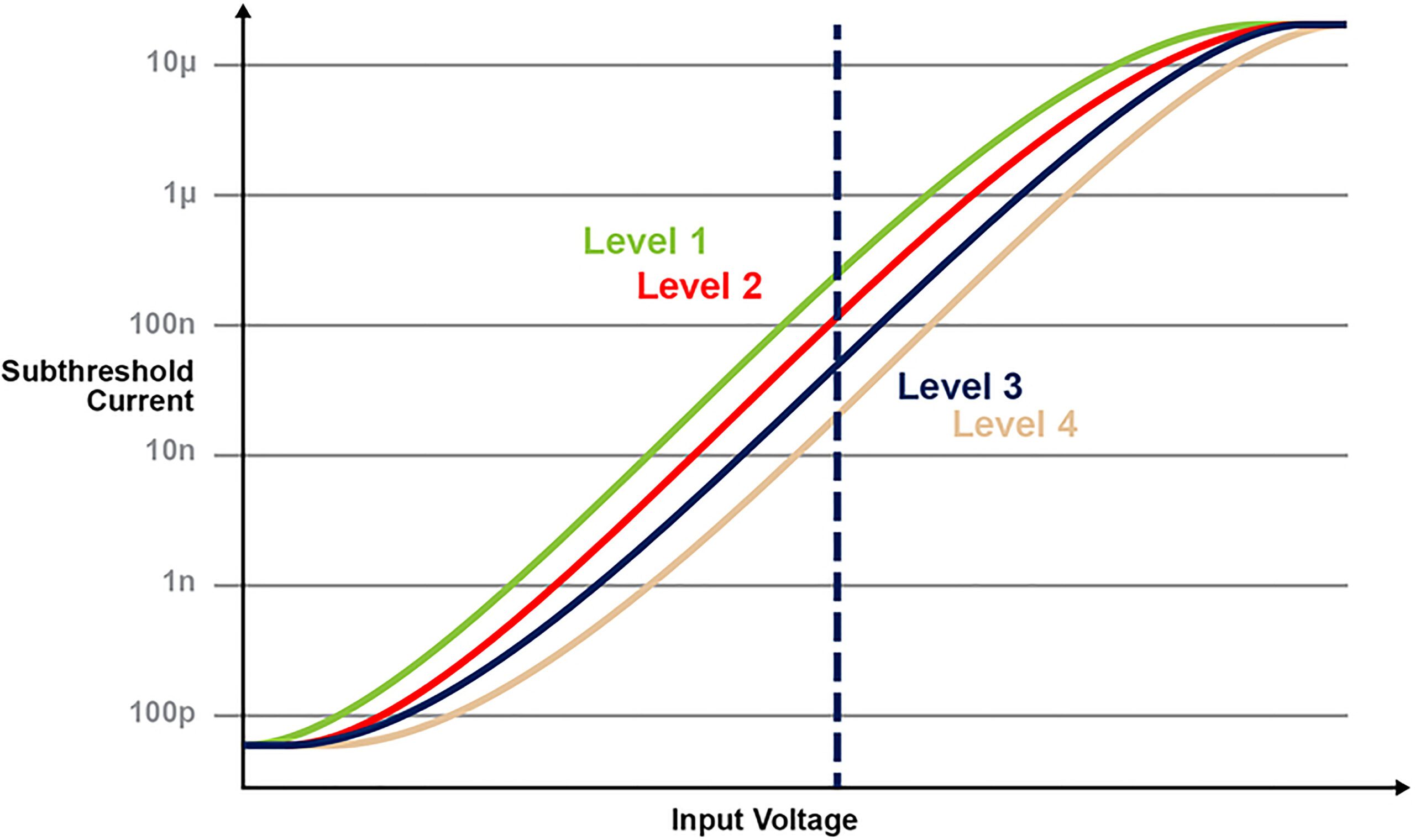
Figura 5: Programmazione livelli Vt nella cella ESF3
Multiply-Accumulate Operation con calcolo in-memory
Ogni cella ESF3 può essere modellata come conduttanza variabile (gm). La conduttanza di una cella ESF3 dipende dalla floating gate Vt della cella programmata. Un weight da un modello riconosciuto è programmato come floating gate Vt della cella di memoria, quindi, gm della cella rappresenta i weights dei modelli riconosciuti. Applicando sulla cella ESF3 una tensione di ingresso (Vin), la corrente di uscita (Iout) sarebbe data dall’equazione Iout = gm * Vin, che è l’operazione di moltiplicazione tra la tensione di ingresso e il weight memorizzato sulla cella ESF3. La Figura 6 di seguito illustra il concetto di multiply-accumulate in una configurazione di piccolo array (array 2×2) in cui l’operazione di accumulo viene eseguita sommando le correnti di uscita dalle celle (da operazione di moltiplicazione) collegate alla stessa colonna (ad esempio I1 = I11 + I21). A seconda dell’applicazione, la funzione di attivazione può essere eseguita all’interno del blocco ADC oppure con un’implementazione digitale esterna al blocco di memoria.
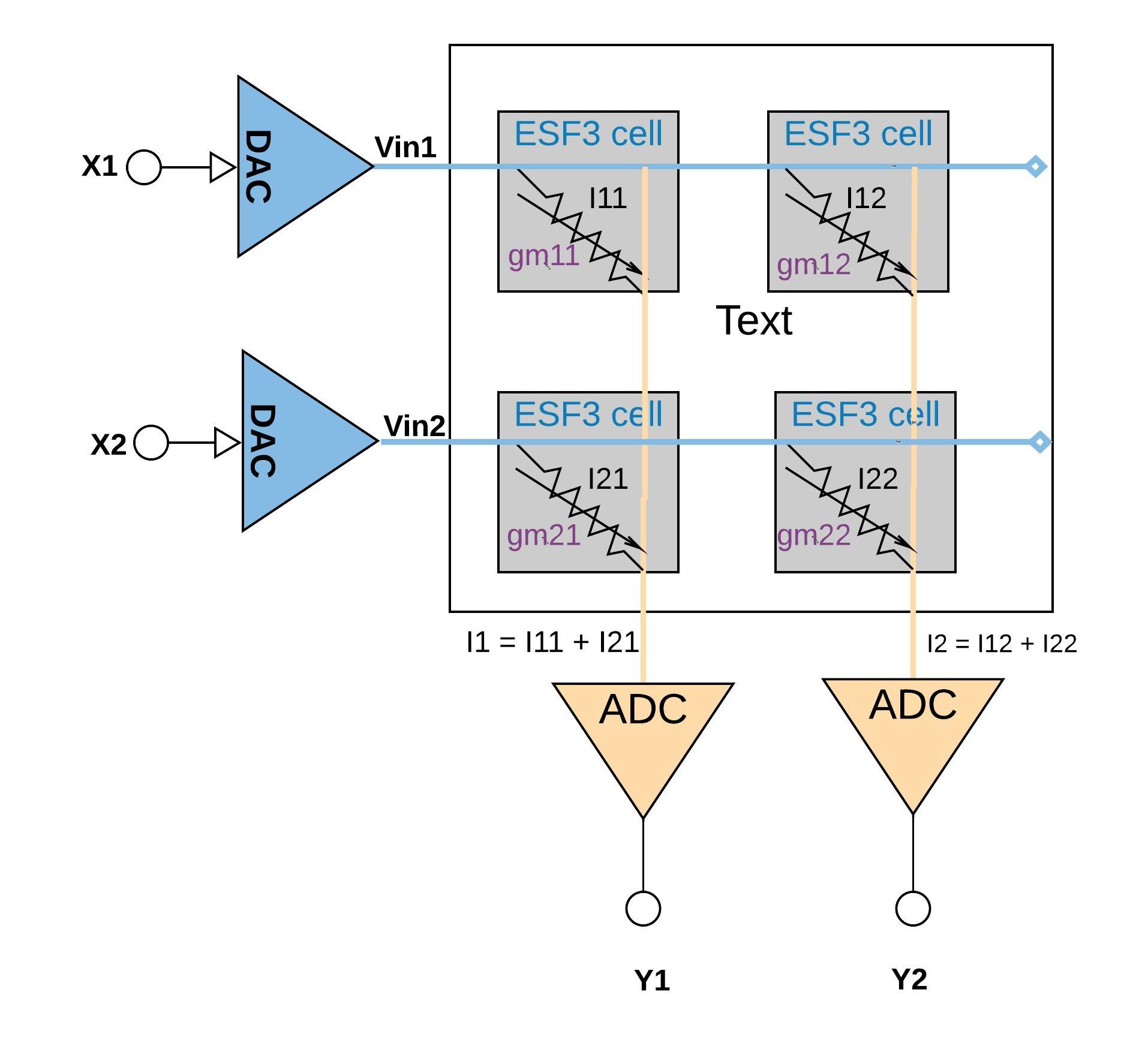
Figura 6: multiply-accumulate operation con array ESF3 (2×2)
Per illustrare ulteriormente il concetto ad un livello superiore, i weights individuali di un modello preparato sono programmati come floating gate Vt della cella di memoria, quindi tutti i weights di ogni layer del modello preparato (diciamo un layer completamente connesso) possono essere programmati su un array di memoria che somiglia fisicamente ad una matrice di weights, come illustrato nella Figura 7. Per un’operazione di inferenza, un ingresso digitale, diciamo pixel dell’immagine, viene prima convertito in un segnale analogico utilizzando un digital-to-analog converter (DAC) quindi applicato all’array di memoria. L’array esegue quindi migliaia di operazioni MAC in parallelo per un dato vettore di input e produce un output che può andare alla fase di attivazione dei rispettivi neuroni, e che può quindi essere riconvertito in segnali digitali utilizzando un analog-to-digital converter (ADC). I segnali digitali vengono quindi elaborati per il raggruppamento prima di passare al layer successivo.
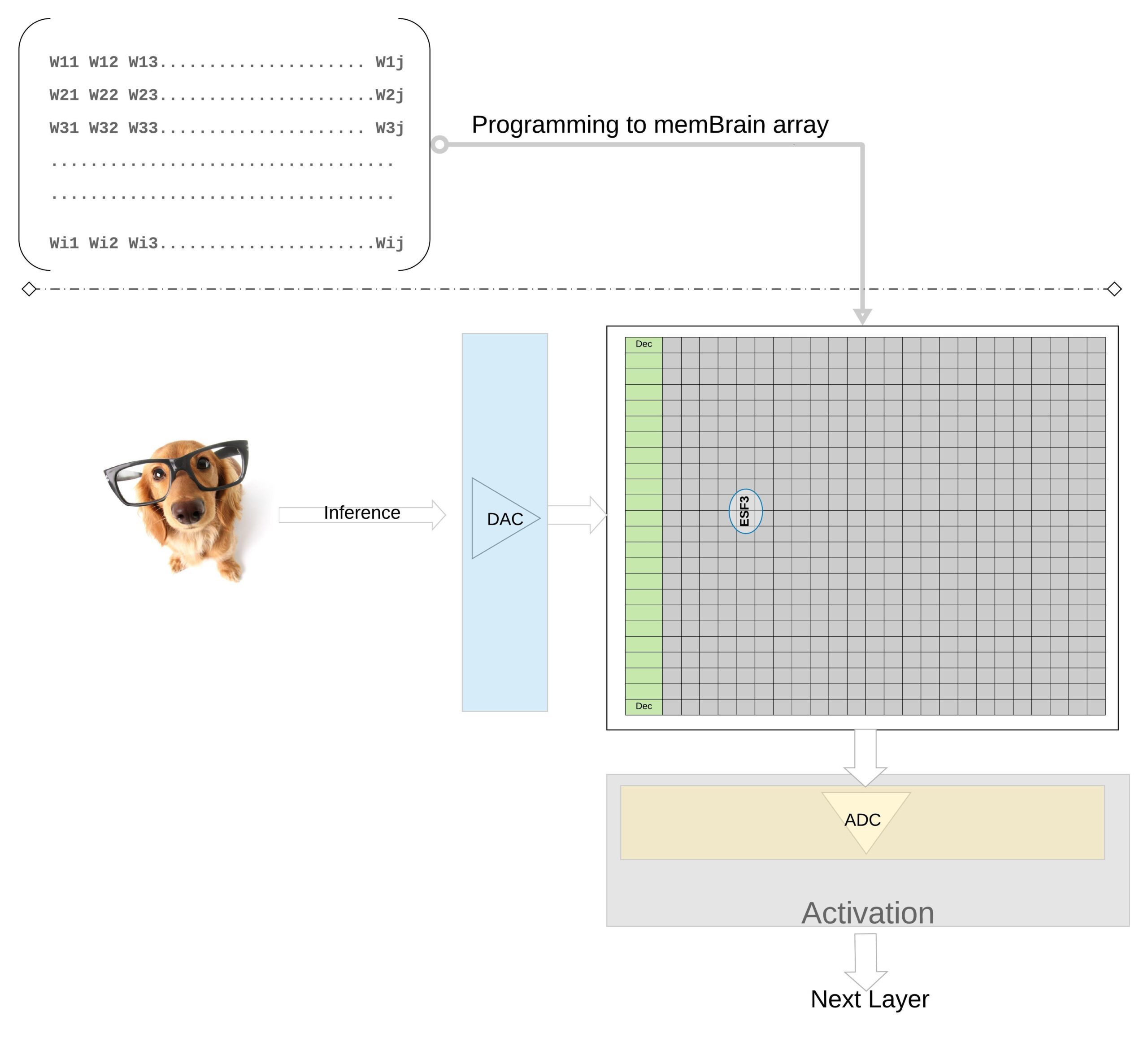
Figura 7: Weight Matrix Memory Array per Inferenza
Questo tipo di architettura di memoria è molto modulare e flessibile. Molte tessere memBrain possono essere unite per costruire una varietà di modelli di grandi dimensioni con un mix di matrici di weight e neuroni, come illustrato nella Figura 8. In questo esempio, una configurazione di tessere 3×4 viene cucita insieme con una struttura analogica e digitale tra le tessere, e i dati possono essere spostati da un riquadro all’altro tramite bus condiviso.
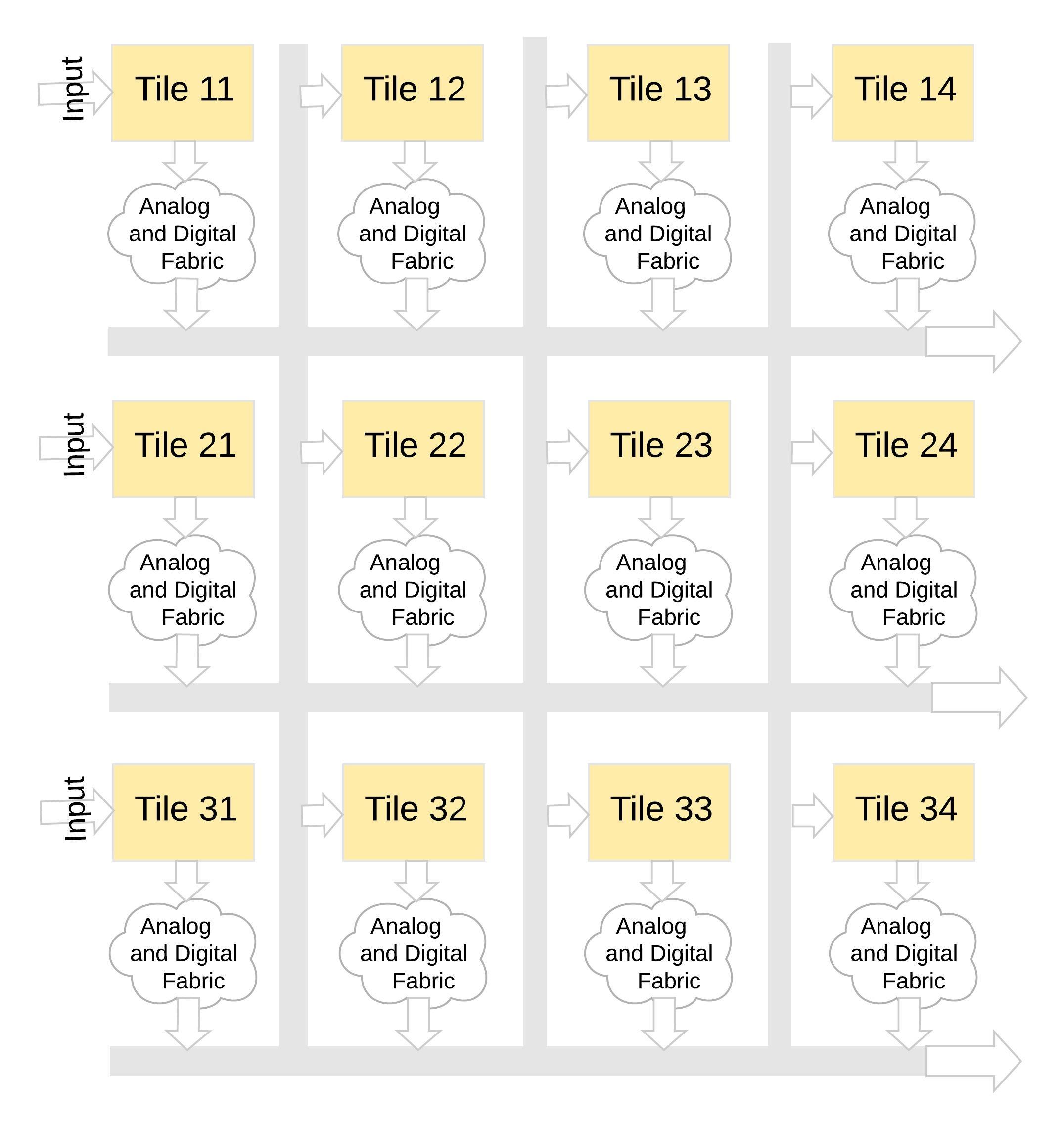
Figura 8: memBrain™ Modulare
Finora abbiamo discusso principalmente dell’implementazione del silicio di questa architettura. La disponibilità di un Software Development Kit (SDK) (Figura 9) aiuta con la distribuzione della soluzione. Oltre al silicio, l’SDK facilita l’implementazione del motore di inferenza. Il flusso dell’SDK è training-framework agnostic. L’utente può creare un modello di rete neurale in uno qualsiasi dei framework disponibili come TensorFlow, PyTorch o altri, utilizzando il calcolo in virgola mobile come desiderato. Una volta creato un modello, l’SDK aiuta a quantizzare il modello di rete neurale formato e a mapparlo sull’array di memoria in cui è possibile eseguire la moltiplicazione della matrice vettoriale con il vettore di input proveniente da un sensore o da un computer.
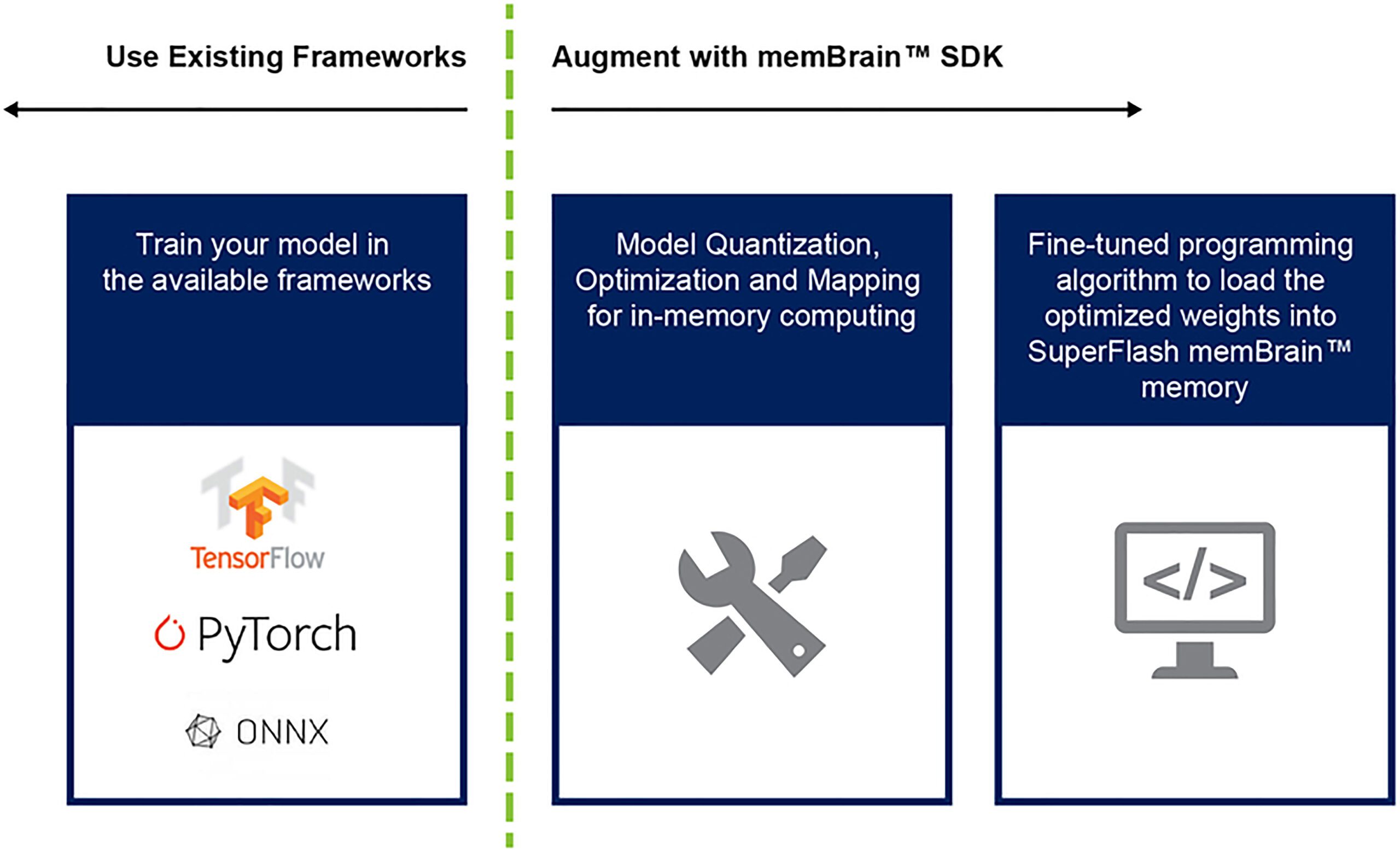
Figura 9: memBrain™ SDK Flow
I vantaggi di questo approccio alla memoria multilivello con le sue capacità di calcolo in-memory includono:
- Extreme low power: questa tecnologia è progettata per applicazioni low-power. Il principale vantaggio energetico deriva dal fatto che si tratta di una soluzione di calcolo in-memory, quindi l’energia non viene sprecata nel trasferimento di dati e weights da SRAM/DRAM durante il calcolo. Il secondo vantaggio energetico deriva dal fatto che le celle flash funzionano in modalità sottosoglia con valori di corrente molto bassi, quindi la dissipazione di potenza attiva è molto bassa. Il terzo vantaggio è che non c’è quasi nessuna dissipazione di energia durante la modalità di standby poiché la cella di memoria non volatile non ha bisogno di alcuna alimentazione per mantenere i dati per dispositivi always-on. L’approccio è anche adatto per sfruttare la scarsità di weights e dati di input. La bitcell di memoria non si attiva se il dato o il weight in ingresso è zero.
- Footprint ridotto del package: la tecnologia utilizza un’architettura di cella split-gate (1.5T), mentre una cella SRAM in un’implementazione digitale si basa su un’architettura 6T. Inoltre, la cella è una bitcell molto più piccola rispetto ad una cella SRAM 6T. Oltre a ciò, una cella può memorizzare tutto il valore intero a 4 bit, a differenza di una cella SRAM che richiede 4*6 = 24 transistor per farlo. Ciò fornisce un ingombro del chip sostanzialmente inferiore.
- Minori costi di sviluppo: a causa dei colli di bottiglia delle prestazioni della memoria e delle limitazioni dell’architettura von Neumann, molti dispositivi appositamente progettati (come Jetsen di Nvidia o TPU di Google) tendono ad utilizzare geometrie più piccole per ottenere più prestazioni per watt, il che è un modo costoso per risolvere la sfida dell’Edge Computing. Con l’approccio alla memoria multilivello che utilizza metodi di calcolo analogici on-memory, il calcolo viene eseguito su chip in celle flash in modo da poter utilizzare geometrie maggiori e ridurre costi delle maschere e tempi di preparazione.
Le applicazioni di edge computing mostrano grandi promesse. Tuttavia, prima che l’edge computing possa decollare, ci sono sfide in termini di potenza dissipata e costi ancora da risolvere. Un grosso ostacolo può essere rimosso utilizzando un approccio alla memoria che esegue calcoli on-chip nelle celle flash. Questo approccio si avvale di una soluzione tecnologica di memoria multilivello, già standard di fatto, collaudata in produzione e ottimizzata per le applicazioni di Machine Learning.
[/boris]