Non ci sono prodotti a carrello.

L’esplosione generale del volume di dati ha portato ad un’enorme crescita delle applicazioni di Intelligenza Artificiale (AI) e Machine Learning (ML), in cui la memoria e l’archiviazione sono fattori chiave per il successo e la velocità delle applicazioni associate. I sistemi di memoria e archiviazione tradizionali non sono progettati per affrontare una sfida come l’accesso a questi set di dati di così grandi dimensioni quindi, un importante ostacolo da superare per le applicazioni AI e ML che stanno entrando tra le applicazioni più importanti in IT, è la riduzione del tempo complessivo di ritrovamento ed elaborazione per garantire il successo nel funzionamento di questi sistemi.
Prima di entrare nel vivo dei dettagli del perché memoria e archiviazione siano essenziali per le applicazioni AI e ML, è importante capire come queste funzionano. La memoria, e più precisamente DRAM, è necessaria come luogo dove tenere i dati che devono essere trasformati il più rapidamente possibile in informazioni utili. La conservazione, o Flash, più specificamente è necessaria per archiviare sia i dati grezzi che i dati che sono stati già trasformati in modo tale che non vadano persi. Il processo base per la memoria e l’archiviazione dei dati è “acquisire, trasformare e decidere”, il più rapidamente possibile.
Server e AI
I server utilizzati per lo sviluppo dell’IA sono passati da una configurazione centrata su CPU a quella centrata su più GPU. I server AI hanno indici di calcolo e di memoria significativamente maggiori rispetto ai server tradizionali, necessari visti i loro flussi di lavoro, multipli e rapidi. Lo sviluppo dell’AI sta spingendo i contenuti più in alto nel panorama hardware mentre gli sviluppatori passano dalle architetture tradizionali a quelle che sfruttano le nuove tecnologie per accelerare i flussi di lavoro.
Secondo Gartner, una delle principali società di ricerca e consulenza che fornisce una approfondita visione per quanto riguarda le tecnologiche aziendali, sia gli Inferencing Server che i Training Server per le applicazioni AI e ML offrono maggiori velocità di elaborazione grazie a memoria e archiviazione.
Gli Inferencing Server, secondo Gartner, usano un algoritmo di apprendimento automatico specializzato nel fare previsioni. I dati IoT possono essere utilizzati come input per un modello di machine learning specializzato, consentendo previsioni che possono indirizzare la logica decisionale sul dispositivo, sull’Edge gateway o altrove nel sistema IoT. Questi server offrono prestazioni di elaborazione notevolmente migliorate, avvicinandosi al 20% in più di DRAM rispetto a un server standard.
I Training Server, come ad esempio i server GPU basati su Nvidia, collegati in grandi training network, sono ciò che consente ai prodotti Facebook di eseguire il riconoscimento di oggetti e volti e la traduzione di testi in tempo reale, oltre a descrivere e comprendere i contenuti di foto e video. Le capacità apprese durante il deep learning training vengono messe a frutto. I Training Server utilizzano le schede acceleratrici di Nvidia, per esempio, e offrono circa 2,5 volte più DRAM di un server standard.
[boris]
Memorie DRAM per AI
Per migliorare le prestazioni nell’elaborazione parallela mediante GPU sono necessarie maggiore larghezza di banda della memoria e bassa latenza, in grado di offrire quell’aumento di larghezza di banda, velocità di elaborazione e flussi di lavoro richiesti dalle applicazioni AI e ML. L’obiettivo è passare dai dati grezzi a quelli analizzati da processare con una latenza più bassa. Le GPU utilizzate nei training server devono essere abbinate al giusto tipo e quantità di memoria al fine ottimizzare le prestazioni. GPU diverse hanno requisiti di memoria diversi. In un esempio di sistema di intelligenza artificiale, il DGX-1 di Nvidia ha 8 GPU ciascuna con 16 GB di memoria interna. Il requisito di memoria principale del sistema è 512 GB, raggiunto da 16x LRDIMM DDR4 da 32 GB. Gli LRDIMM sono progettati per massimizzare capacità e larghezza di banda nei server AI, specialmente quando le CPU non forniscono abbastanza canali di memoria per accogliere più di 8 RDIMM. Questa è la limitazione delle CPU Broadwells che si trovano all’interno del DGX-1. Tipi diversi di memoria e diversi scenari di popolazione DIMM nei server richiedono compromessi tra prestazioni e capacità. Gli LRDIMM sono progettati per ridurre al minimo il carico massimizzando al contempo la capacità. Gli LRDIMM utilizzano un chip buffer per prestazioni scalabili. Gli RDIMM sono in genere più veloci e migliorano l’integrità del segnale disponendo di un registro sul modulo DIMM per bufferizzare i segnali di comando e indirizzo tra ciascuna delle DRAM sul modulo DIMM e il controller di memoria. Ciò consente a ciascun canale di memoria di utilizzare fino a tre DIMM dual-rank. Gli LRDIMM utilizzano buffer di memoria per consolidare i carichi elettrici dei rank sull’LRDIMM in un singolo carico elettrico, consentendo loro di avere fino a otto rank su un singolo modulo DIMM. Con gli RDIMM, le prestazioni del sistema diminuiscono quando tutti I connettori sono utilizzati; ciò si verifica nelle CPU Broadwell e nelle generazioni precedenti di CPU Intel. Con Skylake, come generazione di CPU Intel Cascade Lake, i limiti del canale di memoria non sono più presenti, lo stesso vale per le generazioni di CPU AMD Roma e Milano. Pertanto, gli RDIMM sono la soluzione più veloce ed economica disponibile sul mercato.
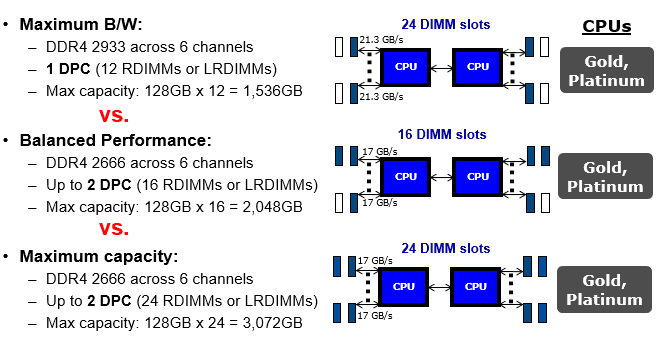
Figura 1. Rappresentazione grafica di Larghezza di Banda Vs. Prestazioni nel caso di utilizzo DIMM riferiti a CPU Intel Cascade Lake
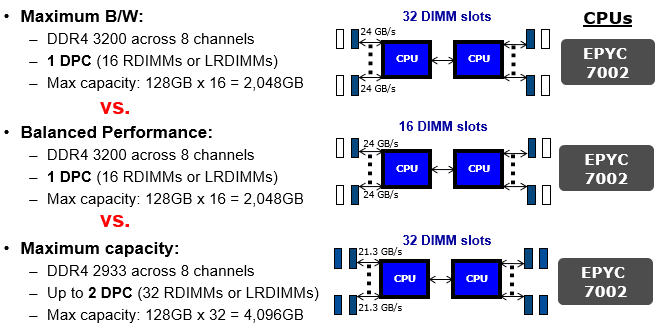
Figura 2. Rappresentazione grafica di Larghezza di Banda Vs. Prestazioni nel caso di utilizzo DIMM riferiti a CPU AMD Rome
Flash Storage per AI
Secondo The Register, “Flash, con la sua combinazione di bassa latenza e throughput elevato, è attualmente considerata la migliore soluzione per l’archiviazione AI, anche se molto dipende anche dal modo in cui viene implementato il sottosistema di archiviazione. In generale, un array di dischi può avere una latenza di decine di millisecondi, mentre quella Flash è in genere dell’ordine di decine di microsecondi, o anche fino a circa mille volte più veloce. Queste velocità di elaborazione così significativamente più elevate sono necessarie, per eseguire le attività multiple richieste nella maggior parte degli utilizzi AI e ML.
Flash, come soluzione di archiviazione, offre numerosi vantaggi e benefici a queste applicazioni AI e ML. La capacità Flash di gestire un throughput elevato di dati con una latenza estremamente bassa si traduce nella capacità di consentire alle applicazioni di accedere ed elaborare i dati più rapidamente, oltre ad elaborare più richieste in parallelo. Lo schema dell’archiviazione Flash, rispetto a quello di lettura/scrittura dei tradizionali dischi rigidi, consente di trovare ed elaborare i dati molto più rapidamente, “poiché impiega esattamente lo stesso tempo per leggere da un qualsiasi punto del chip, a differenza dei dischi rigidi dove la rotazione della superficie del disco e il tempo impiegato per spostare le testine di lettura/scrittura sopra il cilindro esatto sul disco causano ritardi variabili. ”
(The Register) L’archiviazione flash ha un consumo energetico inferiore per il suo utilizzo, il che può far risparmiare sui costi per quelle applicazioni, o utenti, aziendali che richiedono soluzioni di archiviazione su larga scala.
Gli SSD NVMe sono la scelta ottimale per i server AI e ML rispetto agli SSD SATA. Lo storage NVMe evita il collo di bottiglia SATA collegandosi tramite bus PCIe (Peripheral Component Interconnect Express) direttamente alla CPU del computer. Un’unità basata su NVMe può scrivere su disco fino a 4 volte più velocemente e i tempi di ricerca sono fino a 10 volte più brevi. Nel caso degli SSD NVMe le richieste di lettura/scrittura sono state ottimizzate. Le unità SATA supportano una coda I/O singola con 32 accessi. Gli SSD basati su NVMe supportano più code I/O con un valore massimo teorico di 64.000 code, ciascuna delle quali consente 64.000 voci per un totale di 4.096 miliardi di voci. Il software del controller dell’unità NVMe è inoltre progettato per creare e gestire le code I/O. (Fonte: Computer Weekly, agosto 2019, How to deploy NVMe flash storage for artificial intelligence, di Eric Ebert).
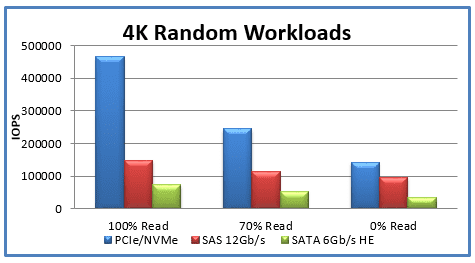
Figura 3. Confronto tra le prestazioni di SSD basato su SATA e NMVe basato su carichi di lavoro casuali 4K
Fonte: https://itpeernetwork.intel.com/why-you-should-care-about-nvm-express/#gs.9h7yfs
Infine, la tabella seguente (Figura 4) delinea i tipi e le densità di memoria e archiviazione utilizzati in alcuni dei server AI più comuni.
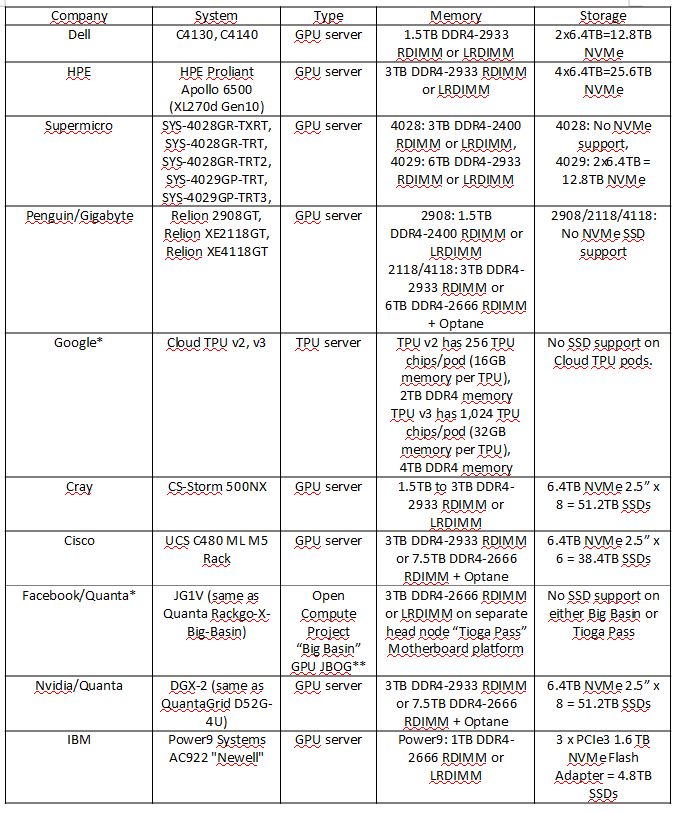
Figura 4. Requisiti di Memoria e Storagre dei Server AI At-A-Glance
* Nota: Hyperscaler come Facebook e Google compartimenteranno e separeranno calcolo e archiviazione nei loro elementi dedicati.
** JBOG significa “Just a Bunch of Graphic Cards” o anche “Just a Bunch of GPUs”. Questo termine è molto simile a JBOD riferito allo spazio di archiviazione, che sta per “Just a Bunch of Disks”.
I progettisti di applicazioni di Artificial Intelligence e Machine Learning hanno validi motivi per considerare attentamente le specifiche della memoria e delle soluzioni di archiviazione integrate nelle loro applicazioni, poiché l’utilizzo delle soluzioni giuste può fare la differenza tra prestazioni o guasti nella stessa applicazione, o anche tra prestazioni e prestazioni ottimali per soddisfare le esigenze sia dell’applicazione che dei suoi utenti. La cosa più importante da ricordare è che la memoria e l’archiviazione devono eseguire le operazioni di “acquisire, trasformare e decidere” il più rapidamente possibile. Questo può in definitiva essere la differenza tra il successo o il fallimento di una applicazione.
[/boris]