Non ci sono prodotti a carrello.
Autori: Manisha Agrawal – Product Marketing Jacinto™ Processors
L’espansione dell’automazione continua a crescere dalla fabbrica fino alla porta di casa
Quando i consumatori ordinano un prodotto on-line, l’automazione interviene per aumentare l’efficienza in ogni passaggio del processo, dalla creazione di materie prime al miglioramento della produttività del magazzino, fino ad agevolare la consegna a domicilio, talvolta anche solo nel giro di poche ore. Per far sì che questi notevoli miglioramenti dell’automazione proseguano, sarà necessario migliorare la percezione e l’intelligenza delle macchine facendo sì che commettano meno errori, il che è ottenibile portando l’intelligenza artificiale (IA) nel campo dei dispositivi edge.
La creazione di sistemi più veloci, più intelligenti e più accurati richiede più dati da più sensori, oltre a quantità crescenti di potenza di calcolo. Tuttavia, maggiori quantità di dati e potenza di calcolo presentano delle sfide in termini di prestazioni di un sistema, oltre agli aspetti legati alla sua potenza e ai requisiti di costo. L’ottimizzazione di un sistema e la riduzione dei tempi dei cicli di sviluppo necessitano di un approccio pratico alla progettazione di sistemi di IA edge.
L’IA edge: una definizione
L’IA edge prevede che gli algoritmi di IA vengano elaborati su dispositivi locali anziché sul cloud; questa soluzione sta cambiando ciò che è possibile realizzare in applicazioni industriali e automotive, dove le reti DNN (deep neural network) costituiscono il componente algoritmico principale. Per poter funzionare in modo efficiente in ambienti con spazi ridotti, limitazioni in termini di dissipazione del calore e costi, le applicazioni di IA edge richiedono un’elaborazione ad alta velocità e bassa potenza, oltre a interazioni avanzate esclusive per l’applicazione e le sue attività. La Figura 1 mostra alcune delle applicazioni in cui l’elaborazione IA edge può essere utilizzata per migliorare le prestazioni e l’efficienza. Ad esempio, i sistemi di IA edge che utilizzano l’input di visione possono implementare una singola telecamera per il controllo di qualità su una linea di produzione oppure più telecamere per contribuire al supporto della sicurezza funzionale su un’auto o in un robot mobile.

Figura 1. L’intelligenza edge esiste in molte applicazioni diverse
I sistemi di IA edge possono contribuire a migliorare l’efficienza in magazzini e fabbriche, rendere le città, l’edilizia e l’agricoltura più sicure ed efficienti, nonché rendere intelligenti le case e gli spazi di vendita al dettaglio. Diamo un’occhiata ad alcuni sistemi che richiedono un’elaborazione efficiente dell’IA edge:
Sistemi avanzati di assistenza alla guida (ADAS). La tecnologia ADAS fornisce informazioni sull’ambiente che circonda un veicolo per rendere la guida più pratica, meno stressante e più sicura. La maggior parte delle funzionalità ADAS è costituita da sistemi basati sulla visione, che acquisiscono input ad alta risoluzione da più sensori di telecamere e utilizzano algoritmi di deep learning e visione computerizzata per interpretare tali immagini.
Robot mobili autonomi e droni. Per i robot commercializzabili, il sistema su chip (SoC) deve elaborare stack complessi di percezione e navigazione ad alte velocità e bassa potenza, con costi di sistema ottimizzati. Il SoC deve inoltre alleggerire il carico di attività a intenso utilizzo della capacità di calcolo, come il dewarping delle immagini, la stima della profondità stereo, il ridimensionamento in scala, la generazione piramidale delle immagini e il deep learning per ottenere la massima efficienza di sistema possibile.
Carrelli della spesa intelligenti. La maggior parte dei carrelli della spesa intelligenti è dotata di numerosi sensori di visione in grado di rilevare automaticamente gli articoli mediante telecamere e visione computerizzata. I carrelli della spesa intelligenti possono calcolare i totali degli ordini quando gli articoli vengono posti nel carrello, consigliare articoli da aggiungere alla lista degli acquisti e permettere ai clienti di pagare la spesa direttamente sul carrello, consentendo quindi loro di personalizzare ulteriormente la loro esperienza di shopping ed evitare le code alla cassa.
Edge AI box. Le edge AI box sono un’estensione intelligente dei sistemi di telecamere utilizzati nell’automazione per la vendita al dettaglio, nel monitoraggio di fabbrica e per la costruzione di sistemi di sorveglianza. Nonostante i limiti di spazio le sfide in termini di potenza e dissipazione del calore, l’IA ad alto throughput consente ai box di eseguire un’elaborazione intelligente per un maggior numero di telecamere.
Telecamere di visione artificiale. Le telecamere di visione artificiale per il riconoscimento ottico dei caratteri, l’identificazione di oggetti, il rilevamento di difetti e la guida di bracci robotizzati sfruttano tecnologie di IA embedded per semplificare ulteriormente lo sviluppo dei prodotti e migliorare l’accuratezza del sistema.
La Tabella 1 mostra i requisiti di sistema di varie applicazioni.
|
Robotica ADAS |
Vendita al dettaglio intelligente |
Visione artificiale |
Edge AI Box |
|
|
Acceleratore di deep learning |
||||
|
Elaborazione ISP (image signal processing) multicamera |
||||
|
Acceleratori di visione |
||||
|
Acceleratori di profondità e movimento |
||||
|
Switch Ethernet |
||||
|
Switch PCIe (Peripheral Component Interconnect Express) |
||||
|
Sicurezza funzionale |
Tabella 1. Requisiti chiave per l’elaborazione e componenti dei sistemi di IA edge.
Che cos’è un sistema di IA edge efficiente?
In un sistema di IA edge efficiente, le DNN non possono funzionare da sole. Un sistema di IA efficiente richiede una complessa pipeline di visione, che include spesso l’elaborazione di immagini da telecamera singola o più telecamere, la visione computerizzata tradizionale e in alcuni casi addirittura più DNN. Alcune applicazioni potrebbero richiedere inoltre encoder e decoder video. Per elaborare tutti questi input, il sistema necessita di capacità di calcolo ad alte prestazioni. Inoltre, il sistema potrebbe richiedere maggiore protezione e sicurezza funzionale, facendo crescere la complessità e i costi del sistema stesso.
Un sistema di IA edge efficiente dovrebbe essere ottimizzato dal punto di vista di:
- Prestazioni. Il processore embedded deve essere in grado di fornire la velocità, la latenza e l’accuratezza richieste dal sistema, funzionando contemporaneamente in modo affidabile, anche in ambienti gravosi.
- Vincoli di progettazione. Il processore deve operare in progetti con limitazioni di potenza e termiche, compresi i progetti privi di ventola, deve disporre di raffreddamento passivo o dover funzionare per molte ore alimentato a batteria. Il processore deve inoltre essere conforme alle specifiche di dimensione e peso per rispondere alle limitazioni fisiche.
- Costo. Disporre di elaborazione ad alte prestazioni ed efficace dal punto di vista dei costi dà come risultato la massima riduzione possibile della distinta base (BOM).
Per costruire un sistema di IA edge efficiente, i progettisti dovrebbero valutare quale architettura e quali core siano i più adatti a svolgere le attività richieste dal sistema.
La scelta di un’architettura SoC
Esistono due tipologie di progettazione per processori embedded: architettura omogenea e architettura eterogenea, di solito con integrazione di funzionalità di elaborazione specializzate per gestire determinate attività. È opportuno valutare quale architettura sia meglio indicata per soddisfare le esigenze del sistema di IA edge in questione, a seconda delle tipologie di core richieste.
Lo scopo di un sistema di IA edge è eseguire attività di IA, visione, video e altre sul core più adatto, in modo che il sistema risultante sia ottimizzato in termini di prestazioni per watt e di prestazioni per TOPS al secondo, nonché per costi, dimensioni e peso. Un’architettura eterogenea dotata dei core giusti per l’attività giusta è fondamentale per i sistemi di IA edge.
Non tutti i processori con architetture eterogenee sono progettati allo stesso modo. Un silicon vendor deve selezionare le giuste funzioni di elaborazione o i processi e decidere se accelerare tali funzioni a livello hardware o renderle configurabili o programmabili. Inoltre deve badare all’integrazione dei core nel sistema. L’architettura del bus e il sottosistema di memoria devono consentire uno spostamento efficiente dei dati fra i core.
I sistemi di IA edge basati sulla visione possono risultare inefficaci se il SoC è dotato delle tipologie di core errate per l’accelerazione delle attività o se troppi core non sono gestiti in modo efficiente o, ancora, se presenta un’infrastruttura di bus e un sottosistema di memoria non efficienti.
Tipologie di core programmabili e acceleratori
Diamo un’occhiata alle possibili tipologie di core nei sistemi di IA edge:
CPU
Le unità di elaborazione centrale (CPU) sono unità di elaborazione per uso generico in grado di gestire carichi di lavoro sequenziali. Sono dotate di grande flessibilità di programmazione e traggono vantaggio da una vasta base di codice già esistente. In generale, la maggior parte dei sistemi di IA edge è dotata di due-otto core CPU per gestire piattaforme e applicazioni ricche di funzionalità. I sistemi dotati solo di CPU non sono tuttavia particolarmente indicati per attività altamente specializzate come l’imaging a livello di pixel, la visione computerizzata e l’elaborazione di reti CNN (convolutional neural network). Inoltre, le CPU presentano un elevato consumo di energia, nonostante abbiano il throughput più basso fra tutti i diversi tipi di core. Un sistema di CPU single-core abbinato a blocchi hardware dedicati, come accelerazione IA ed elaborazione delle immagini, può essere utilizzato per soddisfare i requisiti di budget energetico delle applicazioni a basso costo.
GPU
Le unità di elaborazione grafica (GPU) sono dotate di centinaia o migliaia di piccoli core che ben si adattano a svolgere attività di elaborazione parallele. Progettate originariamente per implementare una sequenza di operazioni grafiche, le GPU sono diventate comuni in applicazioni di deep learning e sono particolarmente utili per l’addestramento delle DNN. Uno degli svantaggi principali è il fatto che, a causa dell’alto numero di core, le GPU consumano molta energia e presentano requisiti di memoria su chip più elevati.
DSP
I processori di segnale digitale (DSP) sono core specializzati ed efficienti dal punto di vista energetico, progettati tipicamente per risolvere numerosi problemi matematici complessi. I DSP elaborano dati in tempo reale a bassa potenza provenienti da sensori di visione del mondo reale, audio, vocale, radar e sonar. I DSP contribuiscono a massimizzare l’elaborazione per ciclo di clock. Tuttavia, non sono semplici da programmare, in quanto richiedono di avere dimestichezza con le caratteristiche dell’hardware DSP, con l’ambiente di programmazione e con l’ottimizzazione del software DSP per ottenere le massime prestazioni.
ASIC
I circuiti ASIC (application-specific integrated circuit) e gli acceleratori offrono il massimo delle prestazioni con il minimo consumo energetico per le applicazioni di sistema. Esistono delle scelte particolarmente apprezzate quando si conoscono i kernel dei core per la funzione che si desidera accelerare. Ad esempio, il calcolo core per le CNN comprende sempre delle moltiplicazioni di matrici. Per le attività tradizionali di visione computerizzata, gli acceleratori hardware dedicati possono calcolare operazioni come il ridimensionamento in scala delle immagini, la correzione delle distorsioni degli obiettivi e il filtraggio del rumore.
FPGA
Gli FPGA (field-programmable gate array) sono una categoria di circuiti integrati in cui è possibile riprogrammare e prendere di mira i blocchi hardware per applicazioni specifiche. Presentano un minore consumo di energia rispetto alle GPU e alle CPU, ma utilizzano più energia degli ASIC. Tuttavia, l’hardware è difficile da programmare, e richiede esperienza in linguaggi di descrizione hardware come Verilog o Very High Speed IC Hardware Description Language.
Progettare sistemi di IA edge con processori di visione di TI
La gamma di processori di visione di TI è stata creata per consentire un’elaborazione IA efficiente e scalabile in applicazioni in cui le limitazioni in termini di dimensioni ed energia sono aspetti fondamentali della progettazione.
Questi processori, che comprendono le famiglie di processori AM6xA e TDA4, vantano un’architettura SoC che comprende un’estesa integrazione per sistemi di visione, tra cui le CPU Arm® Cortex®-A72 o Cortex-A53, memoria interna, interfacce e acceleratori hardware in grado di fornire da 2 a 32 TOPS (teraoperazioni al secondo) per l’elaborazione IA per il deep learning.
La famiglia AM6xA utilizza MPU Arm Cortex-A MPU per alleggerire il carico di attività a intenso utilizzo della capacità di calcolo, come l’inferenza di deep learning, l’imaging, la visione e l’elaborazione video e grafica, spostandolo su acceleratori hardware e core programmabili, come mostrato in Figura 2. L’integrazione di componenti di sistema avanzati in questi processori permette ai progettisti dell’IA edge di semplificare la distinta base del sistema. Questa gamma di processori comprende opzioni di elaborazione scalabili che vanno da processori AM62A per applicazioni a bassa potenza con una o due telecamere all’AM68A (fino a otto telecamere) e all’AM69A (fino a 12 telecamere).
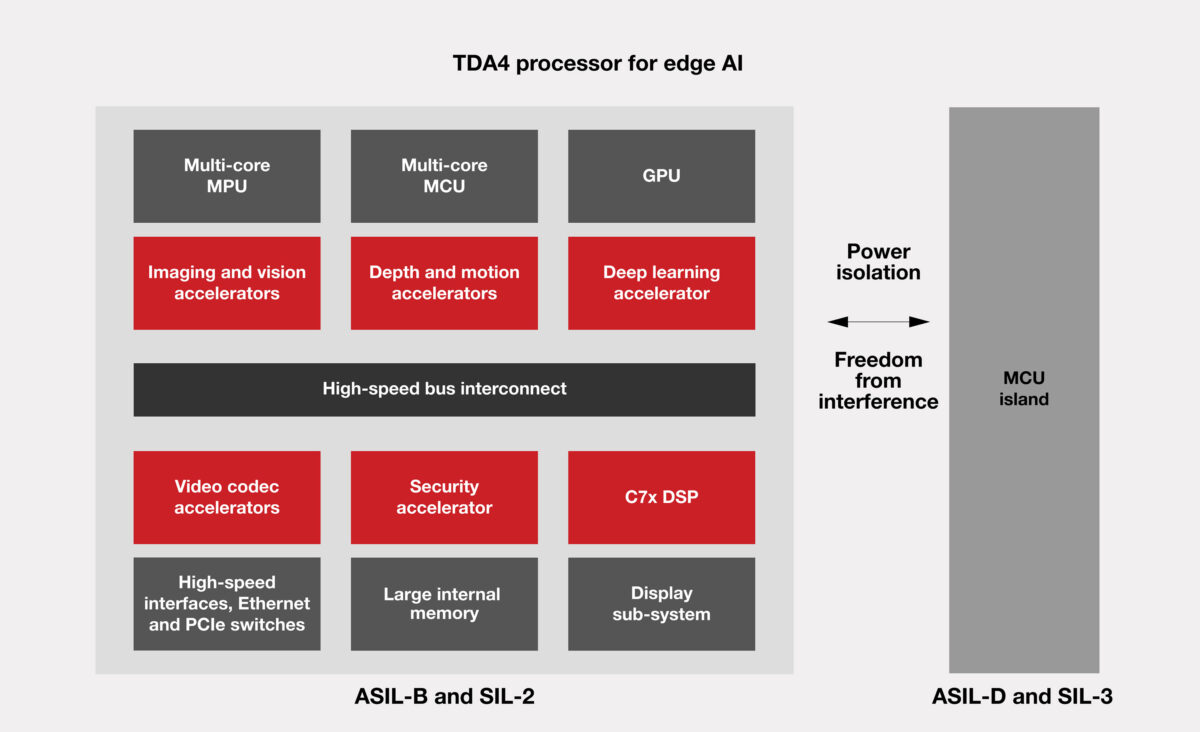
Figura 2. Suddivisione dei sistemi di IA edge con processore di visione di TI.
Acceleratore di deep learning
Benché siano idonee per altre attività, le CPU e le GPU non sono i core più indicati per l’accelerazione di attività di deep learning. Le CPU presentano limitazioni in termini di throughput e consumano molta energia, mentre le GPU sono i maggiori consumatori di energia tra tutti i core e presentano un grande footprint di memoria.
I processori di IA di visione di TI integrano un acceleratore di deep learning che comprende un acceleratore MMA (matrix multiplication accelerator) all’interno di un ASIC, accoppiato a un DSP C71 programmabile. L’MMA rende possibile un’accelerazione tensoriale ad alte prestazioni (4K moltiplicazioni-accumulazioni per ciclo fisse a 8 bit) e a basso consumo energetico, mentre il DSP C71 accelera le operazioni vettoriali e scalari e gestisce l’MMA.
La combinazione dell’MMA e del DSP C71 genera un acceleratore che permette di ottenere le massime prestazioni (inferenza al secondo) e la massima potenza (inferenza per watt) nel settore. La flessibilità di programmazione del core C71 consente di tenere il passo delle innovazioni dell’IA. Inoltre, quando non è utilizzato per il deep learning, il core è in grado di elaborare altre attività a intenso utilizzo della capacità di calcolo consumando poca energia.
L’architettura di memoria intelligente rende possibile un elevato utilizzo dell’acceleratore. L’acceleratore è dotato del proprio sottosistema di memoria, di un motore di accesso diretto alla memoria (DMA) programmabile 4D per il trasferimento dati e un hardware di streaming specializzato che è in grado di spostare i dati direttamente dalla memoria esterna alle unità funzionali del core C71 e dell’MMA, bypassando la cache. Le funzionalità di tiling e supertiling riducono al minimo il trasferimento dei dati da e verso la memoria esterna.
La Tabella 2 mostra prestazioni di inferenza fissa a 8 bit su AM68A e su TDA4VM con un acceleratore da 8 TOPS. Le prestazioni riportate sono per batch di dimensione 1 e con una singola LPDD4 a 32 bit.
|
Rete |
Risoluzione immagini |
Frame al secondo (fps) |
|
MobileNet_v1 |
224 × 224 |
741 |
|
Resnet-50 V1.5 |
224 × 224 |
162 |
|
SSD-MobileNets-V1 |
300 × 300 |
385 |
Tabella 2. Benchmark di inferenza su modelli raccomandati MLPerf.
Precisazione: TI ha utilizzato i modelli raccomandati MLPerf e le linee guida per il benchmark di interferenza IA edge. TI non ha ancora presentato i risultati all’organizzazione MLcommons.
Imaging e acceleratori hardware per visione computerizzata
I sistemi di IA edge basati sulla visione comprendono spesso l’elaborazione di immagini da telecamera singola o multipla e tradizionali compiti di visione computerizzata. In una CPU o GPU, queste attività consumano molta energia e presentano delle limitazioni in termini di throughput.
Questa classe di SoC per processori IA edge permette di accelerare attività di visione con elaborazione dei pixel a forza bruta a basso livello con intenso utilizzo della capacità di calcolo a livello hardware, come ISP, correzione della distorsione degli obiettivi, multiscaling e filtraggio bilaterale del rumore in un core acceleratore per l’elaborazione della visione. Un core acceleratore di percezione della profondità e del movimento accelera la stima della profondità stereo e il flusso ottico denso per contribuire a migliorare la percezione dell’ambiente, come mostrato in Figura 3.

Figura 3. Funzioni dell’acceleratore di visione.
L’accelerazione di queste operazioni a livello hardware si traduce in un basso consumo energetico e in dimensioni ridotte. Nonostante queste attività siano accelerate a livello hardware, la loro configurabilità offre la flessibilità per utilizzare le funzioni dell’acceleratore e rispondere al meglio alle esigenze del proprio sistema.
Questa integrazione e questa accelerazione eliminano la necessità di un ISP su misura o di FPGA e libera megahertz della CPU per elaborare attività di imaging e visione a intenso utilizzo della capacità di calcolo nell’hardware. Ad esempio, un singolo core acceleratore di elaborazione della visione è in grado di elaborare fino a otto telecamere da 2 megapixel o due telecamere da 8 megapixel a 30 fps. Un core di accelerazione per l’elaborazione della profondità e del movimento è in grado di eseguire una stima della profondità stereo a 80 megapixel al secondo e di vettori di movimento a 150 megapixel al secondo.
Bus interno e architettura di memoria intelligenti
Il monitoraggio del movimento dei dati e l’architettura di memoria di un processore, al fine di evitare vari blocchi del core e ritardi durante l’esecuzione di più core contemporaneamente, possono contribuire a massimizzare le prestazioni complessive di un sistema.
I processori IA di visione di TI dispongono di un’interconnessione bus ad alta larghezza di banda con un’infrastruttura non bloccante e una grande memoria interna. Vari motori DMA programmabili dedicati automatizzano il movimento dei dati a velocità molto elevate. Questa struttura consente un elevato utilizzo degli acceleratori hardware, con notevoli risparmi in termini di larghezza di banda DDR (double-data-rate). La riduzione del numero delle istanze DDR permette di ridurre la quantità di energia utilizzata dall’accesso DDR, diminuendo quindi il consumo energetico complessivo del sistema.
Ottimizzazione della distinta base del sistema
Diamo un’occhiata alle caratteristiche e ai componenti di sistema integrati avanzati nei SoC di visione di TI che permettono di ridurre i costi in distinta base del sistema per diverse tipologie di applicazioni IA edge:
ISP. Il core ISP integrato elimina la necessità di progettare con un ISP o FPGA esterno. Tutte le applicazioni IA a telecamera singola e multipla, come la visione artificiale, i carrelli della spesa intelligenti, la robotica e gli ADAS, possono trarre vantaggio da questa integrazione.
Sicurezza. Il microcontroller (MCU) di sicurezza conforme ad ASIL D (Automotive Safety Integrity Level) e SIL 3, con core Cortex-R5, contribuisce a raggiungere gli obiettivi di sicurezza senza una MCU di sicurezza esterna. Poiché anche la restante elaborazione è conforme ASIL B/SIL 2, un’architettura di questo tipo consente di realizzare applicazioni per centraline elettroniche per ADAS, robotica, edilizia e agricoltura.
Switch Ethernet e PCIe. Gli switch Ethernet e PCIe integrati eliminano la necessità di componenti switch esterni.
Protezione. Gli acceleratori di protezione integrati offrono supporto di protezione allo stato dell’arte.
Memoria DDR. La protezione di codice a correzione di errore in linea e il minor numero di istanze di memoria DDR (grazie alla memoria intelligente) rispetto alle tipiche architetture di memoria possono tradursi in risparmi sui costi.
Ambiente di sviluppo software facile da usare
Un ambiente software completo, mostrato in Figura 4 e fornito da TI, permette di utilizzare un’architettura eterogenea e di sfruttare l’intero potenziale delle prestazioni del silicio senza dover studiare l’hardware TI o di software proprietario. L’astrazione degli acceleratori hardware tramite driver di qualità a livello di produzione consente di velocizzare lo sviluppo del software, oltre a fornire interfacce con un sistema operativo ad alto livello sulla MPU per lo sviluppo di applicazioni utilizzando API (Application Programming Interface) standard nel settore. Il software a livello inferiore di TI accelera automaticamente attività di imaging, visione, deep learning e multimediali con gli acceleratori hardware corretti, facilitando la programmazione di applicazioni ad alte prestazioni.

Figura 4. Ambiente di sviluppo software per applicazioni IA edge.
Conclusione
L’adozione di un’architettura eterogenea nelle applicazioni è in crescita. I processori IA di visione di TI, con elaborazione accelerata per deep learning, visione e video, integrazione di sistema su misura e integrazione avanzata dei componenti, permettono di realizzare sistemi di IA edge pronti per la commercializzazione e ottimizzati in termini di prestazioni, energia, dimensioni, peso e costi di sistema. L’ambiente di sviluppo software IA edge di TI è costruito intorno ad API open source e standard nel settore, con accelerazione automatica per acceleratori hardware che consentono di velocizzare lo sviluppo di applicazioni IA edge.
L’IA è una tecnologia in rapida evoluzione, che promuove le innovazioni in tutte le dimensioni delle applicazioni IA edge. Questa tecnologia sta espandendo i limiti delle applicazioni che richiedono maggiori esigenze di calcolo. Se realizzata con minore consumo energetico e minori costi di sistema attraverso l’implementazione di un processore embedded, l’IA edge è in grado di dischiudere un intero mondo di nuove possibilità grazie alle applicazioni embedded.