Non ci sono prodotti a carrello.

L’Intelligenza Artificiale (AI) ha la capacità di rendere i sistemi integrati per l’Internet of Things Industriale (IIoT) molto più reattivi e affidabili. Gli utenti stanno già sfruttando la tecnologia per monitorare le condizioni dei macchinari e identificare se un guasto è imminente, oltre a programmare i lavori di manutenzione ordinaria in maniera più conveniente.
Una decisione importante nella diffusione della tecnologia AI nei sistemi integrati consiste nel determinare dove avviene la maggior parte di questa elaborazione di dati. Gli algoritmi AI variano ampiamente nelle prestazioni di calcolo che richiedono, il che avrà una forte influenza su ciò che è necessario per elaborare l’algoritmo e su dove tale elaborazione viene fatta. Ci sono tre approcci chiari per i progettisti di sistemi che sviluppano sistemi integrati basati su AI, tra cui l’utilizzo di un servizio AI basato su cloud, l’implementazione di un sistema con AI integrato o la creazione di algoritmi propri, generalmente basati su software open-source.

Utilizzo di un servizio basato sul cloud
Un’architettura Deep Neural Network (DNN) è un esempio di algoritmo che è particolarmente intensivo nell’elaborazione, soprattutto durante la fase di formazione, dove sono necessari miliardi di calcoli in virgola mobile ogni volta che il modello deve essere aggiornato. A causa dell’intensa richiesta di DNN, l’approccio tipico è quello di inviare dati al cloud per elaborarli a distanza. L’elaborazione nel cloud è già ampiamente utilizzata nell’elettronica di consumo, come gli altoparlanti smart. I dispositivi abilitati all’AI nel controllo industriale possono allo stesso modo sfruttare questa elaborazione remota, così come gli strumenti e i framework creati per lavorare con i servizi cloud, molti dei quali sono forniti in forma open-source.
Un esempio popolare di AI basato su cloud è TensorFlow di Google. Questo fornisce diversi livelli di astrazione per consentirne l’uso da parte degli ingegneri esperti nella creazione di algoritmi AI, così come da parte di chi è appena agli inizi. L’API di Keras, che fa parte del framework di TensorFlow, è stato progettato per rendere più facile l’esplorazione di tecniche di apprendimento automatico e avviare le applicazioni.
Un inconveniente con l’elaborazione basata su cloud, tuttavia, sta nella larghezza di banda di comunicazione necessaria per supportarla. Una connessione internet affidabile è essenziale per mantenere il servizio e vale la pena notare che molte applicazioni consumer di cloud AI si basano su connessioni a banda larga. Le macchine utensili in fabbrica potrebbero non avere accesso ai dati necessari per aggiornare in tempo reale un modello AI remoto.
Svolgendo più elaborazioni localmente, è possibile ridimensionare i requisiti della larghezza di banda, a volte in maniera drastica. Per molte applicazioni industriali, la quantità di dati che deve essere inviata a una postazione remota può essere ridotta notevolmente prestando attenzione al contenuto. In un’applicazione che monitora le variabili ambientali, molte di esse non cambiano per lunghi periodi di tempo. Ciò che è importante per il modello risiede nelle modifiche al di sopra o al di sotto di determinate soglie. Anche se un sensore può avere bisogno di analizzare gli ingressi del sensore millisecondo per millisecondo, la frequenza di aggiornamento per il server cloud può essere dell’ordine di pochi aggiornamenti ogni secondo, o anche meno frequentemente.
La creazione del software per AI
Per forme più complesse di dati, come audio o video, sarà richiesto un maggior grado di pre-elaborazione. L’elaborazione dell’immagine prima di passare l’output a un modello AI può non solo salvare la larghezza di banda delle comunicazioni, ma contribuire a migliorare le prestazioni complessive del sistema. Ad esempio, il denoising prima della compressione migliora spesso l’efficienza degli algoritmi di compressione. Questo è particolarmente importante per le tecniche di compressione con perdita che sono sensibili ai segnali ad alta frequenza. Il rilevamento dei bordi può essere utilizzato con la segmentazione dell’immagine per focalizzare il modello solo su oggetti di interesse. Ciò riduce la quantità di dati irrilevanti che devono essere alimentati al modello, sia durante la formazione che l’inferenza.
[boris]
Sebbene l’elaborazione delle immagini sia un campo complesso, in molti casi gli sviluppatori possono elaborare algoritmi localmente, sfruttando le librerie facilmente disponibili. In questo modo si elimina la necessità di connessioni Internet con larghezza di banda elevata e si può ridurre la latenza. Un esempio popolare è OpenCV (Open Source Computer Vision Library), una libreria open-source per la computer vision, che molti team hanno impiegato per pre-elaborare i dati per i modelli AI. Scritto in C++ per prestazioni elevate, gli sviluppatori possono chiamarlo da codice C++, Java, Python e Matlab, supportando la facile prototipazione prima di portare gli algoritmi a un target integrato.
Utilizzando OpenCV ed elaborando i dati localmente, gli integratori eliminano anche i rischi di sicurezza associati alla trasmissione e all’archiviazione dei dati nel cloud. Tra le principali preoccupazioni tra gli utenti finali ci sono privacy e sicurezza dei dati durante la trasmissione al cloud. La manutenzione preventiva e l’ispezione industriale sono processi critici, che richiedono l’analisi dei dati per essere il più possibile affidabili, ma contengono informazioni che potrebbero essere vantaggiose per concorrenti senza scrupoli, qualora le ottenessero. Altri sistemi, come quelli utilizzati in medicina, affrontano ulteriori questioni riguardanti la protezione della privacy. Sebbene gli operatori del cloud abbiano messo in atto misure per evitare che i dati vengano compromessi, i dati conservati all’interno di ogni dispositivo (per quanto possibile) limitano il rischio di esposizione nel caso in cui un attacco hacker abbia successo.
Oltre al supporto per l’elaborazione delle immagini, recenti versioni di OpenCV integrano il supporto diretto per i modelli di apprendimento automatico costruiti, utilizzando una serie di popolari framework che includono Caffe, PyTorch e TensorFlow. Un metodo che ha dimostrato il successo per molti utenti è quello di utilizzare il cloud per lo sviluppo iniziale e la prototipazione, prima di portare il modello sulla piattaforma integrata.
Le prestazioni sono la preoccupazione principale per qualsiasi modello di apprendimento automatico che è portato su un dispositivo integrato. Poiché i dati di formazione hanno un requisito molto elevato per le prestazioni, un’opzione è quella di farli eseguire su server locali o cloud (a seconda dei problemi di privacy), con l’inferenza – ovvero quando un modello addestrato viene alimentato con dati in tempo reale – eseguita presso il dispositivo stesso.

Quando le prestazioni locali sono un requisito, una possibile soluzione è Avnet Ultra96-V2, che incorpora lo Xilinx Zynq UltraScale+ ZU3EG MPSoC. La combinazione dei core dei processori Arm con motori di elaborazione del segnale incorporati e un array logico completamente programmabile fornisce un supporto efficace per i modelli DNN e le routine di elaborazione delle immagini. L’Ultra96-V2 estende l’intervallo di temperatura del prodotto all’intera gamma industriale, permettendogli di essere utilizzato in prossimità di macchinari che operano in condizioni difficili. La riconfigurazione fornisce la capacità di gestire la formazione a livello locale e l’inferenza dove l’applicazione ha esigenze di alta produttività.
L’inferenza comporta un overhead inferiore rispetto alla formazione e, per i sensori piuttosto che i flussi di immagini, un microcontrollore che esegue il kernel DNN nel software può essere soddisfacente. Ma flussi di velocità di dati più bassi possono essere ancora troppo per essere gestiti da un dispositivo a bassa potenza. Alcuni team utilizzano tecniche di ottimizzazione per ridurre il numero di calcoli necessari per l’inferenza, anche se aumenta la complessità di sviluppo. I modelli di AI spesso contengono un alto grado di ridondanza. Potando le connessioni tra i neuroni e riducendo la precisione dei calcoli a 8 bit interi o a risoluzione ancora più bassa, è possibile registrare un notevole risparmio di potenza di elaborazione.
Utilizzo di un dispositivo Edge con AI integrato
Un’opzione alternativa è quella di avere l’inferenza scaricata su un dispositivo gateway locale. Un gateway potrebbe gestire i compiti di inferenza per un certo numero di nodi di sensori se il throughput per nodo è relativamente basso. Ad esempio, nelle applicazioni di visione computerizzata, non è necessario inviare dati per l’inferenza AI quando lo strumento non è in funzione o caricare una nuova parte per l’ispezione.
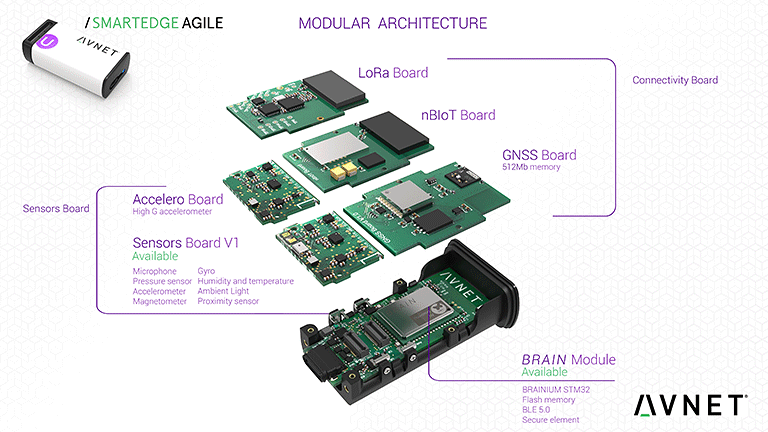
La necessità di distribuire carichi di lavoro, fare il porting e ottimizzare i modelli dai framework orientati al cloud aumentano la complessità dello sviluppo. Un’altra opzione è quella di utilizzare un framework già ottimizzato per l’uso integrato. Un primo esempio è la piattaforma Brainium sviluppata da Octonion. La piattaforma Brainium fornisce un quadro di sviluppo completo rivolto ai sistemi integrati. Il suo ambiente software supporta direttamente la prototipazione, utilizzando sistemi cloud con implementazione su dispositivi IoT e gateway costruiti utilizzando l’hardware SmartEdge Agile di Avnet. L’ambiente software Brainium coordina le attività dei dispositivi, dei gateway e degli strati cloud per formare un ambiente olistico per l’AI. Per rendere possibile la scalabilità di applicazioni a nodi profondamente integrati, l’ambiente offre supporto per diverse tecniche di AI, con una elaborazione meno intensiva di quelle impiegate nei DNN. Il software gateway può essere distribuito su hardware preconfezionato come il Raspberry Pi o qualsiasi piattaforma in grado di eseguire Android o iOS. Dove sono necessarie prestazioni più elevate, lo strato cloud di Brainium può essere distribuito su soluzioni AWS, Microsoft Azure o server personalizzati.
Altri fornitori leader del mercato, come Schneider Electric e Festo, hanno integrato il supporto AI locale nei prodotti di controllo per applicazioni specifiche. Il primo offre l’applicazione Predictive Analytics per identificare sottili cambiamenti nel comportamento del sistema che influenzano le prestazioni. Nel 2018, Festo ha acquisito lo specialista in data-science Resolto e il suo software SCRAITEC apprende lo stato di salute di un sistema, al fine di rilevare ogni anomalia.
L’approccio adottato da un produttore o integratore di apparecchiature originali quando si utilizza l’AI dipenderà dalle circostanze individuali. Oltre alla potenza di elaborazione disponibile, ci saranno altri fattori che incoraggiano l’uso del cloud computing, la costruzione di nuovi software e/o l’integrazione di un dispositivo edge per gestire l’AI. Ad esempio, mentre gli utenti cercano di sfruttare l’analisi dei Big Data, potrebbero voler estrarre le informazioni da molti sistemi in un database più ampio e, quindi, favorire l’uso dei servizi cloud. Altri vorranno garantire elevati livelli di privacy per i loro dati. Laddove l’elaborazione dell’offload è un fattore chiave, ci sono modi per gestirlo, dall’uso di motori di offload basati su gateway locali all’utilizzo esteso del cloud computing. Ciò che è importante è che ci sono numerosi ambienti che consentono una facile prototipazione e la distribuzione all’architettura di vostra scelta.
[/boris]