Non ci sono prodotti a carrello.
L’intrattenimento dei consumatori chiede sempre più esperienze immersive che consentano agli utenti di consumare contenuti in modo indistinguibile dalla realtà fisica. In tali esperienze il suono riveste un ruolo fondamentale. Analog Devices immagina un futuro in cui i sistemi audio basati sulla Vision Intelligence offriranno tecniche di riproduzione del suono sviluppate sulla base di una migliore comprensione del modo in cui la nostra mente elabora e localizza i suoni. Gli innovativi sensori a tempo di volo (ToF) e i migliori DSP offrono la giusta combinazione di tecnologie e costituiscono la piattaforma ideale per realizzare nuove generazioni di sistemi audio immersivi.
Per descrivere un nuovo dispositivo di intrattenimento per i consumatori bisogna citare il termine ‘immersivo’, ma cosa significa veramente? Nel film “Matrix” del 1999 Morpheus chiede a Neo se ciò che annusa, assaggia o tocca è reale, poi prosegue dimostrando che la costruzione della realtà che conosceva inganna questi sensi umani attraverso la computerizzazione. Questo è il significato di vera immersione ed è l’obiettivo delle esperienze immersive artificiali.
In un’esperienza veramente immersiva il suono e il modo di viverla sono due degli elementi più importanti dell’emozione che si prova. Il suono provoca una reazione istintiva nel cervello e apre la strada al modo in cui rispondiamo in ogni situazione. Il cervello utilizza il suono per creare un’immagine più nitida dell’ambiente o della situazione in cui si trova. Il suono riveste un ruolo fondamentale nel fornire l’immersione voluta, convincendo il cervello a credere a un’esperienza immersiva creata artificialmente.
Nel corso degli anni la tecnologia di riproduzione del suono ha fatto notevoli progressi: dal sistema audio monoaurale di base, ossia con un singolo canale audio, si è passati agli attuali sistemi con audio surround, che spaziano da configurazioni 5.1 (6 canali) o 7.1 (8 canali), adatte per impianti home theatre, a configurazioni maggiori con 64 canali e oltre, indicate per gli schermi cinematografici. La percezione spaziale del suono e la sua precisione in questi sistemi sono tuttavia limitate dal numero di altoparlanti e dalla loro posizione.
La una nuova generazione di sistemi audio immersivi verrà creata con nuove tecniche applicate alla riproduzione del suono che si baseranno su una migliore comprensione del modo in cui la nostra mente elabora e localizza il suono. Questi sistemi offriranno un’esperienza sonora immersiva a 360° negli home theatre, senza bisogno di numerosi altoparlanti posizionati intorno all’ascoltatore. Tuttavia la mancanza di una consapevolezza ambientale dell’ascoltatore e l’ambiente di ascolto costituiranno un grosso ostacolo per questi sistemi in termini di soddisfacimento delle richieste di audio immersivo. La fusione tra Vision Intelligence e riproduzione del suono è fondamentale per risolvere tali problemi e realizzare la nuova generazione di sistemi audio immersivi.
Quando ascoltiamo un suono naturale in uno scenario reale, il cervello ricava indizi spaziali sulla sorgente del suono in base a due soli segnali, quelli che arrivano all’orecchio destro e sinistro. In modo simile funziona il nostro sistema di visione binoculare in cui il cervello genera la percezione della profondità confrontando ciò che vede l’occhio destro e sinistro. Il cervello elabora il suono che arriva all’orecchio destro e sinistro e confronta l’ampiezza e i ritardi vicini al luogo della sorgente sonora. Questo sviluppo ha avuto luogo nel processo evolutivo ed è stato fondamentale per la sopravvivenza nei tempi più remoti.
La tecnica di riproduzione audio binaurale mira a riprodurre l’esperienza di ascolto naturale mediante un nuovo metodo di elaborazione in grado di generare gli stessi segnali che arrivano all’orecchio destro e sinistro in uno scenario reale (figura 1). Passare dalla teoria alla pratica è, tuttavia, un’impresa ardua a causa di diversi problemi.
-

Figura 1. In uno scenario naturale con una sorgente sonora x(t), XL (t) è il segnale audio che arriva all’orecchio sinistro, mentre XR (t) è il segnale audio che arriva all’orecchio destro.
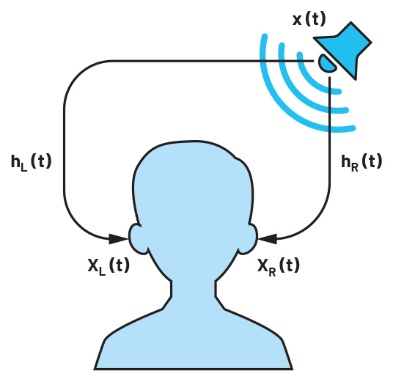
Un metodo semplice per registrare un audio binaurale consiste nell’inserire due microfoni, uno per condotto uditivo di una persona in un ambiente reale, e registrare i segnali sonori in ciascun orecchio: questa è la registrazione binaurale. Il suono viene poi riprodotto nelle orecchie dell’ascoltatore attraverso le cuffie. Ma questa tecnica funziona? In un certo senso sì se l’acquisizione e la riproduzione vengono eseguite per la stessa persona. Il modo in cui il cervello localizza i suoni è il motivo per cui non funzionerebbe per un’altra persona. L’impatto della testa/del padiglione auricolare/del corpo sul suono lascia un’impronta ben precisa nel dominio della frequenza per aiutare il processo di localizzazione del suono nel cervello. Tale impronta varia da una persona all’altra ed è definita funzione di trasferimento della testa (Head-Related Transfer Function, HRTF). Affinché la tecnica binaurale funzioni davvero, è necessario che l’impatto HRTF sul suono venga ricreato con precisione nell’orecchio dell’ascoltatore durante la riproduzione.
Le HRTF devono essere misurate e personalizzate per ogni ascoltatore, non è possibile utilizzare un’unica soluzione. Secondo alcuni studi, la capacità di localizzazione del suono delle persone che ascoltano un audio prodotto usando la HRTF di un’altra persona si riduce notevolmente durante l’esperienza.1,2,3
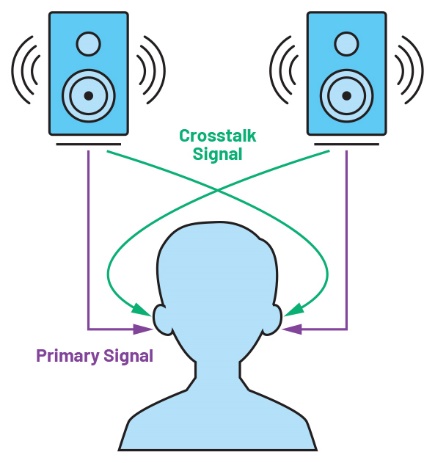
Altri aspetti ancora più importanti volgono a favore dell’audio binaurale rispetto agli altoparlanti. In primo luogo i segnali sonori provenienti da più altoparlanti che interferiscono tra loro, il cosiddetto effetto crosstalk (figura 2), in secondo luogo l’ambiente di ascolto che può contribuire a creare effetti indesiderati sul suono prima che arrivi all’orecchio dell’ascoltatore.
-
Figura 2. Effetto crosstalk negli altoparlanti stereo.
L’effetto crosstalk negli altoparlanti, la necessità di personalizzare la HRTF e l’impatto sull’ambiente di ascolto sono alcuni dei principali ostacoli alla realizzazione dell’obiettivo di simulare una vera esperienza di ascolto naturale. Un sistema di visione in grado di catturare tutti i dettagli necessari e l’ambiente di ascolto possono contribuire a risolvere i problemi associati alla riproduzione audio binaurale.
Ad esempio, è possibile costruire una telecamera che fornisca un algoritmo di Computer Vision per catturare i dettagli strutturali tridimensionali dell’ambiente di ascolto, ossia la forma della stanza di ascolto, i dettagli delle misurazioni geometriche di superfici diverse e degli oggetti presenti. Questi dati possono essere usati per calcolare l’impatto dell’ambiente di ascolto sul suono. In seguito nella riproduzione del suono si possono utilizzare filtri adeguati e i relativi coefficienti per eliminare questo impatto indesiderato. Sebbene questo tipo di sistema non sia estraneo all’audio dell’home theatre, ha sempre fatto ricorso a un microfono per acquisire l’impatto della stanza sul suono durante la procedura di calibrazione che deve essere ripetuta in caso di variazione della posizione di ascolto o di cambiamenti strutturali alla stanza.
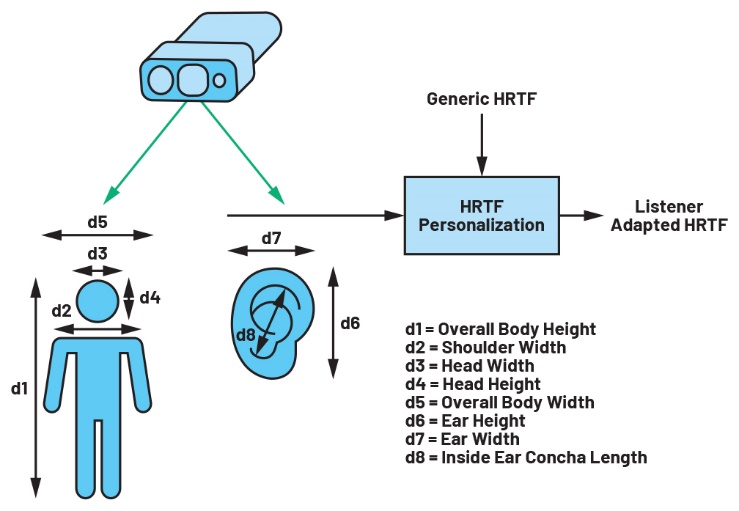
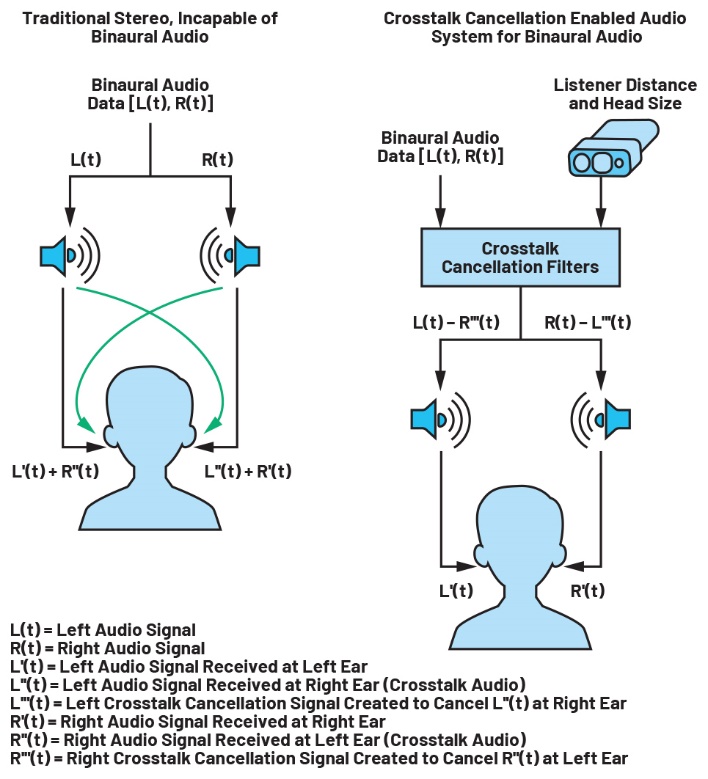
Il sistema di visione può inoltre acquisire misure antropometriche (es. posizione del corpo e dettagli strutturali4) che consentono di eseguire i calcoli necessari a personalizzare la HRTF per fornire indizi spaziali precisi (figura3). Usando le informazioni sulla posizione della testa dell’ascoltatore rispetto all’altoparlante e sulle dimensioni della testa, si può utilizzare un algoritmo di cancellazione del crosstalk per riprodurre l’audio binaurale in tempo reale proveniente dalla configurazione di altoparlanti. In questo modo l’ascoltatore può muoversi senza compromettere l’esperienza sonora ideale (figura 4).
-
Figura 3. Personalizzazione della HRTF mediante misure antropometriche.
-
Figura 4. Uso della cancellazione del crosstalk per consentire la riproduzione audio binaurale con sistemi di altoparlanti a campo libero.
La compromissione della privacy dell’utente costituisce un problema comune associato all’uso dei sistemi di visione. L’elaborazione dell’analisi dei dati di visione con un processore dedicato tutela la privacy dell’utente perché le immagini acquisite con la telecamera dal sistema di visione vengono elaborate in tempo reale e non devono essere memorizzate o trasferite verso un’altra macchina remota.
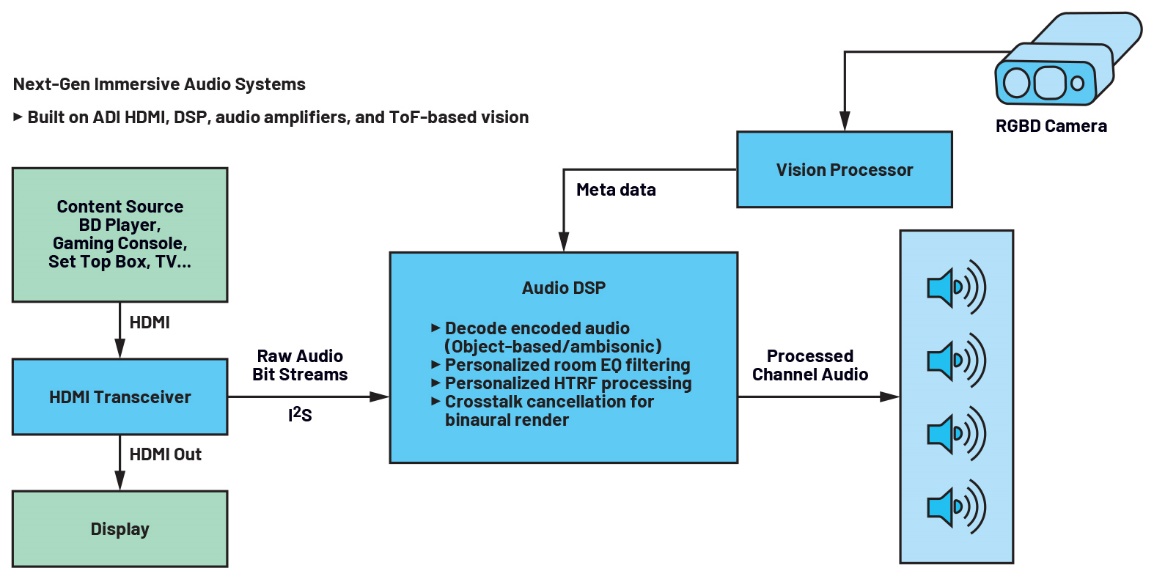
I nuovi DSP SHARC® multicore e gli innovativi sensori ToF di ADI offrono gli ingredienti principali della piattaforma hardware necessaria per realizzare la fusione tra visione e audio e creare una nuova generazione di sistemi audio immersivi (figura 5).
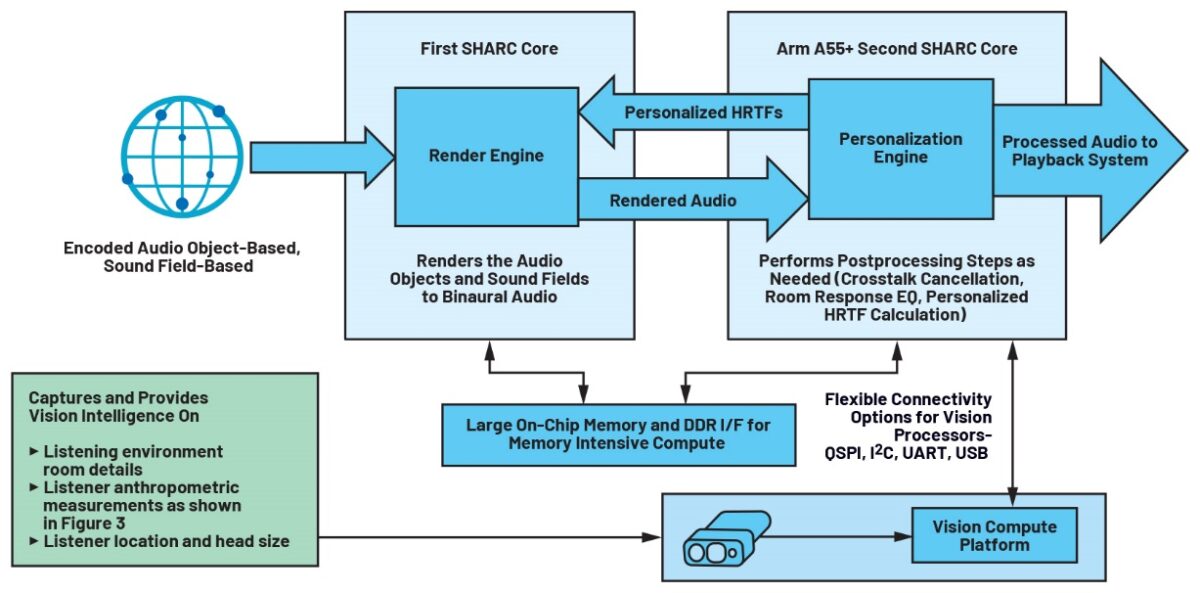
I SOC ADSP-SC598 con dual core SHARC e un core Arm® A55 supportati da una grande memoria interna e un’interfaccia DDR per memoria esterna sono la piattaforma ideale per soddisfare i requisiti di calcolo a bassa latenza e uso intensivo di memoria per un audio veramente immersivo (figura 6). Le risorse di calcolo sul DSP SHARC, come l’ ADSP-SC598, consentono la partizione dei carichi di lavoro associati alla decodifica audio su un core DSP, mentre la post-elaborazione e la personalizzazione della riproduzione audio possono avvenire sul secondo core SHARC. L’Arm A55 può essere utilizzato per una vasta gamma di control processing.6 Il sistema di visione descritto nella figura 5 è realizzabile con una combinazione di RGB e telecamere di profondità oppure una telecamera di profondità autonoma. Il nostro sensore di profondità ToF da 1 MP ad alta risoluzione ADSD3100 cattura mappe di profondità con una risoluzione millimetrica e può operare in presenza di diverse condizioni di illuminazione. Ciò garantisce misurazioni geometriche precise per gli algoritmi di personalizzazione descritti in precedenza (cancellazione crosstalk, equalizzazione della stanza, personalizzazione della HRTF, ecc.).
L’ADTF3175 è un modulo ToF da 1 MP con campo visivo da 75 × 75, basato sul sensore di profondità ToF ADSD3100. Il modulo comprende l’obiettivo e il filtro ottico passa-banda per realizzare i sistemi di visione, una sorgente di illuminazione a infrarossi completa di ottiche, diodo laser e relativo driver, il fotorilevatore, una memoria flash e i regolatori di potenza per generare le tensioni di alimentazioni locali. Il modulo è completamente calibrato per diverse distanze operative e risoluzioni. Per completare il sistema di rilevamento della profondità, i dati dell’immagine grezza provenienti dal modulo ADTF3175 vengono elaborati esternamente dal processore del sistema host o dal processore del segnale di profondità (ISP). L’uscita dei dati di immagine dell’ADTF3175 si interfaccia elettricamente con il sistema host tramite un’interfaccia MIPI (Mobile Industry Processor Interface) CSI-2 (Camera Serial Interface 2) a 4 corsie. Il modulo può essere programmato e controllato tramite l’interfaccia seriale a 4 fili (SPI) e l’interfaccia I2C.
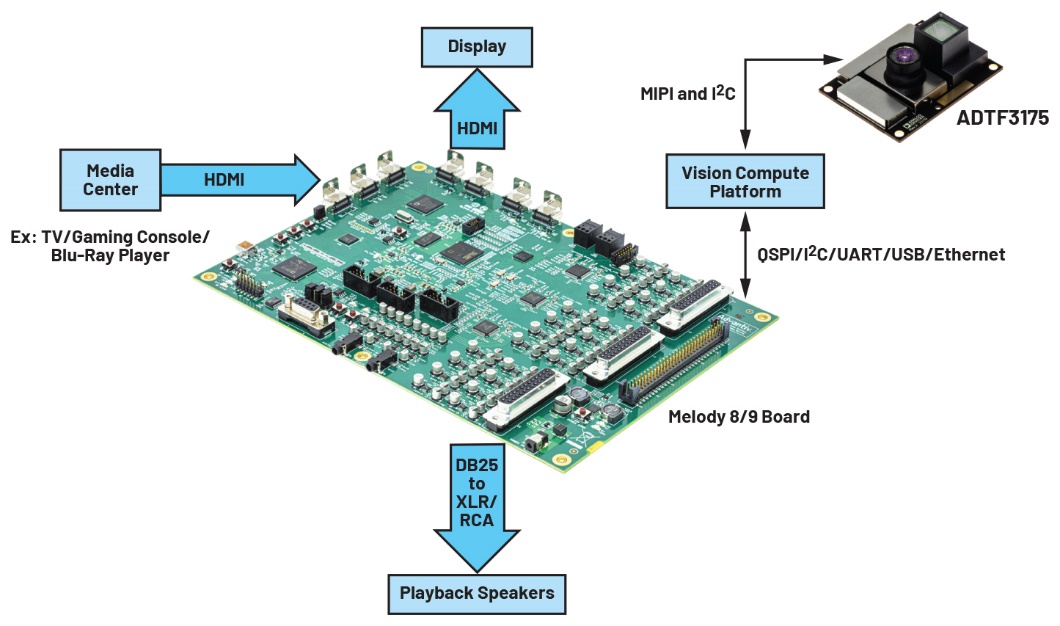
La scheda di valutazione EVAL-MELODY-8/9 attualmente disponibile, le schede EV-2159X/SC59x-EZKIT e CrossCore®Embedded Studio (ambiente di sviluppo Eclipse-based) consentono di diventare operativi con i SOC ADSP per attività in tempo reale e debug application.7
La piattaforma Melody è la soluzione che ADI propone per AVR e soundbar. Combina componenti ADI per video, DSP, audio, potenza e software in un sistema combinato che consente di accedere al mercato rapidamente, con tecnologie di ultima generazione.8
Il modulo ToF ADTF3175 è collegabile a una piattaforma di Computer Vision e a una scheda Melody per creare una piattaforma hardware per la nuova generazione di sistemi audio immersivi (figura 7). Al modulo ToF ADTF3175 possibile abbinare una telecamera RGB per ottenere un dispositivo RGBD per un’analisi della visione ottimizzata.
-
Figure 5. Sistemi audio immersivi di nuova generazione.
-
Figure 6. Suddivisione dei sistemi audio immersivi di nuova generazione.
-
Figura 7. Realizzazione di sistemi audio immersivi con piattaforme ADI.
Conclusioni
Attraverso la sua gamma di soluzioni per DSP, transceiver HDMI, amplificatori di classe D e sensori ToF, ADI è impegnata a realizzare sistemi audio immersivi efficaci, in grado di riprodurre suoni indistinguibili da quelli presenti nel mondo reale.