Non ci sono prodotti a carrello.

È difficile sottovalutare le promesse fatte dal machine learning, la cui ultima evoluzione, il deep learning, è stata definita una tecnologia fondamentale che avrà un impatto sul mondo pari a quello di Internet o, prima ancora, del transistor.
Spinto dai notevoli sviluppi nella potenza di calcolo e dalla disponibilità di enormi data set etichettati, il deep learning ha già portato a notevoli miglioramenti nella classificazione delle immagini, negli assistenti virtuali e nei giochi, e probabilmente farà lo stesso per innumerevoli altri settori. Rispetto al machine learning tradizionale, il deep learning è in grado di offrire una maggiore accuratezza, più versatilità e un migliore utilizzo dei big data, il tutto con una minore esperienza richiesta in quel campo.
Affinché il machine learning possa tenere fede a questa promessa in molti settori, è necessario poter implementare l’inferenza (la parte che esegue l’algoritmo di machine learning addestrato) in un sistema embedded. Questa implementazione presenta tutta una serie di sfide e requisiti particolari. In questo white paper verranno trattate le sfide poste dall’implementazione del machine learning in sistemi embedded e le principali considerazioni da tenere presente nella scelta di un processore embedded per il machine learning.

Figura 1. Flusso di sviluppo del deep learning tradizionale.
Addestramento e inferenza
Nel sottoinsieme del machine learning costituito dal deep learning vi sono due elementi principali: addestramento e inferenza, che possono essere eseguiti su piattaforme di elaborazione completamente diverse, come mostrato in Figura 1, in basso. L’aspetto dell’addestramento del deep learning avviene normalmente offline su desktop o sul cloud e comprende il caricamento di grandi data set etichettati in una rete neurale DNN (deep neural network). Le prestazioni in tempo reale o la potenza non costituiscono un problema in questa fase. Il risultato della fase di addestramento è una rete neurale addestrata che, una volta implementata, è in grado di svolgere un compito specifico, ad esempio ispezionare una bottiglia su una catena di montaggio, contare e tenere traccia delle persone all’interno di una stanza o determinare se una banconota è contraffatta. L’implementazione della rete neurale addestrata su un dispositivo che esegua l’algoritmo è nota come inferenza. Dati i vincoli imposti da un sistema embedded, la rete neurale viene spesso addestrata su una piattaforma di elaborazione diversa da quella che esegue l’inferenza. Il presente documento si concentra sulla scelta del processore per la parte di inferenza del deep learning. I termini «deep learning» e «machine learning» nelle restanti parti del presente documento fanno riferimento all’inferenza.
Il machine learning all’edge
L’idea di avvicinare il computing al punto in cui sensori acquisiscono i dati, ossia al bordo della rete (edge) è un aspetto fondamentale dei moderni sistemi embedded. Con il deep learning, questa idea diventa ancora più importante al fine di rendere possibili l’intelligenza e l’autonomia all’edge. Per molte applicazioni, ad esempio sui macchinari automatizzati o sui robot industriali in fabbrica, negli aspirapolvere a guida automatica in casa e sui trattori agricoli, l’elaborazione deve avvenire in locale.
Le ragioni dell’elaborazione in locale possono essere piuttosto diversificate, a seconda dell’applicazione. A seguire sono descritti alcuni degli aspetti che giustificano la necessità di elaborazione in locale:
- Affidabilità. Spesso fare affidamento su una connessione Internet non è un’opzione praticabile.
- Bassa latenza. Molte applicazioni richiedono una risposta immediata. Un’applicazione potrebbe non essere in grado di tollerare il ritardo di invio dei dati in un altro luogo per la loro elaborazione.
- I dati potrebbero essere privati e, quindi, non dovrebbero venire trasmessi o archiviati esternamente.
- Larghezza di banda. L’efficienza in termini di larghezza di banda della rete è spesso un aspetto chiave. Realizzare una connessione a un server per ogni caso d’uso non è una scelta sostenibile.
- La potenza è sempre una priorità per i sistemi embedded. Lo spostamento dei dati consuma energia. Più i dati devono viaggiare lontano, maggiore è l’energia necessaria.
La scelta di un processore embedded per il machine learning
Molti degli aspetti che richiedono un’elaborazione in locale si sovrappongono a quelli intrinseci dei sistemi embedded, in particolare la potenza e l’affidabilità. I sistemi embedded presentano inoltre molti altri fattori di cui tenere conto, che sono correlati alle limitazioni fisiche del sistema o causati da esse. Esistono requisiti spesso non flessibili in materia di dimensioni, memoria, potenza, temperatura, longevità e, ovviamente, costi.
Oltre alla necessità di trovare un compromesso tra tutti i requisiti e gli aspetti relativi a una data applicazione embedded, vi sono alcuni importanti fattori da considerare nella scelta di un processore su cui eseguire l’inferenza del machine learning per l’edge:
- Considerare l’applicazione nel suo insieme. Una delle prime cose da comprendere prima di scegliere una soluzione di elaborazione è l’ambito dell’applicazione nel suo insieme. L’esecuzione dell’inferenza costituirà l’unica elaborazione richiesta o sarà presente una combinazione tra visione artificiale tradizionale e l’aggiunta di un’inferenza di deep learning? Spesso si può ottenere una maggiore efficienza se un sistema esegue un tradizionale algoritmo di visione computerizzata ad alto livello, per poi eseguire il deep learning quando necessario. Ad esempio, un’immagine di input intera ad elevata frequenza di frame al secondo (fps) può eseguire degli algoritmi classici di visione computerizzata per svolgere operazioni di tracciamento degli oggetti, utilizzando il deep learning su sottoregioni identificate dell’immagine a fps inferiori per classificare gli oggetti. In questo esempio, la classificazione di oggetti su più sottoregioni potrebbe richiedere istanze multiple di inferenza o eventualmente anche inferenze diverse in esecuzione su ciascuna sottoregione. Nell’ultimo caso, è necessario scegliere una soluzione di elaborazione in grado di eseguire sia la visione computerizzata tradizionale sia il deep learning, oltre a istanze multiple di diverse inferenze di deep learning. La Figura 2 mostra un esempio di utilizzo per tracciatura di oggetti multipli attraverso sottoregioni di un’immagine e di esecuzione della classificazione su ciascun oggetto tracciato.
- Scegliere il giusto punto di prestazione. Dopo essersi fatti un’idea dell’ambito dell’applicazione nel suo insieme, è importante capire il livello di prestazioni di elaborazione necessario per soddisfare i requisiti dell’applicazione. Questo punto può essere difficile da capire quando si tratta del machine learning, in quanto le prestazioni sono in gran parte specifiche dell’applicazione. Ad esempio, le prestazioni di una rete di tipo CNN (convolutional neural net) che classifica gli oggetti in un flusso video dipende da quali livelli sono utilizzati nella rete, dalla profondità della rete, dalla risoluzione del video, dai requisiti in termini di fps e da quanti bit sono utilizzati per i pesi della rete, solo per nominare alcuni requisiti. In un sistema embedded, tuttavia, è importante tentare di ottenere una misura delle prestazioni necessarie, in quanto utilizzare un processore troppo potente per affrontare il problema si traduce solitamente in svantaggi in termini di aumento della potenza, delle dimensioni e/o dei costi. Anche se un processore potrebbe essere in grado di raggiungere i 30 fps a 1080p di ResNet-10, un modello di rete neurale comunemente utilizzato in applicazioni di deep learning centralizzate e ad alta potenza, si tratta probabilmente di un’esagerazione per un’applicazione che esegue una rete più adatta all’uso embedded in una regione di interesse di 244 x 244.
- Pensare per l’embedding. La scelta della rete giusta è importante tanto quanto la scelta del giusto processore. Non tutte le architetture di reti neurali sono adatte a un processore embedded. Limitare i modelli a quelli con meno operazioni agevola il conseguimento di prestazioni in tempo reale. È consigliabile dare priorità ai benchmark di una rete più adatta all’uso embedded, ossia ad una rete che sacrifichi l’accuratezza a favore di sensibili risparmi in termini computazionali, anziché rivolgersi a reti più note, come AlexNet e GoogleNet, che non sono state progettate per lo spazio embedded. Analogamente, occorre andare alla ricerca di processori in grado di sfruttare in modo efficiente gli strumenti offerti da queste reti nello spazio embedded. Ad esempio, le reti neurali sono in grado di tollerare molti errori: l’utilizzo della quantizzazione è un metodo valido per ridurre i requisiti prestazionali con un calo minimo in termini di accuratezza. I processori in grado di supportare la quantizzazione dinamica e sfruttare in modo efficiente altri «trucchetti» come la sparsity (limitazione del numero di pesi non-zero) sono scelte utili nello spazio embedded.
- Garantire la facilità d’uso. La facilità d’uso si riferisce sia alla facilità di sviluppo sia alla facilità di valutazione. Come menzionato in precedenza, il corretto dimensionamento delle prestazioni del processore è un importante aspetto progettuale. Il modo migliore per farlo correttamente è far girare la rete scelta su un processore già esistente. Alcune proposte offrono strumenti che, data una topologia di rete, mostrano le prestazioni e l’accuratezza ottenibili su un dato processore, rendendo quindi possibile una valutazione delle prestazioni senza la necessità dell’hardware vero e proprio o della finalizzazione di una rete. Per lo sviluppo, la possibilità di importare facilmente un modello di rete addestrato da framework diffusi come Caffe o TensorFlow è un must.
Inoltre, il supporto di ecosistemi aperti, come ONNX (Open Neural Network eXchange) permette di supportare una base ancora più ampia di framework da utilizzare per lo sviluppo.
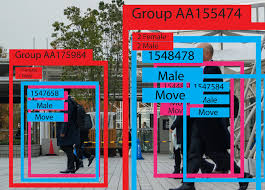
Figura 2. Esempio di classificazione degli oggetti tramite embedded deep learning.
Esistono numerosi tipi diversi di processori da valutare nella scelta per il deep learning e ciascuno di essi presenta dei punti di forza e dei punti deboli. Le GPU (Graphics Processing Unit) sono solitamente la prima tipologia presa in considerazione, in quanto sono ampiamente utilizzate per l’addestramento delle reti. Nonostante presentino notevoli capacità, le GPU hanno avuto problemi nel prendere piede all’interno dello spazio embedded per via dei vincoli di potenza, dimensione e costo che si trovano spesso nelle applicazioni embedded.
I «motori inferenziali» ottimizzati per potenza e dimensioni sono sempre più disponibili al crescere della popolarità del deep learning. Questi motori sono proposte hardware specializzate e mirate specificatamente ad eseguire l’inferenza di deep learning. Alcuni motori sono ottimizzati al punto di utilizzare pesi da 1 bit e possono svolgere semplici funzioni come il rilevamento di frasi chiave, ma ottimizzare fino a questo punto al fine di risparmiare potenza e capacità di calcolo va a limitare la funzionalità e la precisione del sistema. I motori inferenziali più piccoli potrebbero non essere abbastanza potenti se l’applicazione necessita di classificare gli oggetti o di eseguire lavori minuziosi. Nel valutare questi motori, è necessario assicurarsi che siano delle dimensioni giuste per l’applicazione. Una limitazione di questi motori inferenziali si verifica quando l’applicazione necessita di capacità di elaborazione supplementare al di fuori dell’inferenza di deep learning. È abbastanza frequente, inoltre, che il motore debba essere utilizzato parallelamente a un altro processore nel sistema, agendo come co-processore di deep learning.
Un sistema su circuito integrato (SoC) è spesso una valida scelta nello spazio embedded in quanto, oltre ad alloggiare diversi elementi di elaborazione in grado di eseguire l’inferenza di deep learning, un SoC integra anche molti componenti necessari per coprire l’applicazione embedded nel complesso. Alcuni SoC integrati sono completi di display, grafica, accelerazione video e funzionalità di networking industriale, rendendo possibile una soluzione a chip singolo che non si limita all’esecuzione del deep learning.
Un esempio di SoC ad elevata integrazione per deep learning è il dispositivo AM5749 di Texas Instruments mostrato in Figura 3. L’AM5749 è dotato di due core Arm® Cortex®-A15 per l’elaborazione di sistema, due core C66x DSP (Digital Signal Processing) per l’esecuzione di algoritmi di visione artificiale tradizionale e due Embedded Vision Engine (EVE) per eseguire l’inferenza. La proposta software TIDL (TI deep learning) include la libreria TIDL, che gira su core C66x DSP o sugli EVE, rendendo possibile l’esecuzione simultanea di inferenze multiple sul dispositivo. Inoltre, l’AM5749 offre un ricco set di periferiche, un sottosistema di comunicazione industriale (ICSS, industrial communications subsystem) per l’implementazione di protocolli di fabbrica come EtherCAT e l’accelerazione per la codifica/decodifica video e la grafica in 3D e 2D, in modo da agevolare l’utilizzo di questo SoC in uno spazio embedded in grado di eseguire anche il deep learning.
La scelta di un processore per un’applicazione embedded è spesso il componente più critico da scegliere per un prodotto, e ciò vale per molti prodotti in grado di rivoluzionare un settore e che porteranno il machine learning all’edge. Si spera che questo documento sia riuscito nel suo scopo di fornire informazioni sugli aspetti da considerare nella scelta di un processore: considerare l’applicazione nel suo insieme, scegliere il giusto punto di prestazione, pensare per l’embedding e garantire la facilità d’uso.
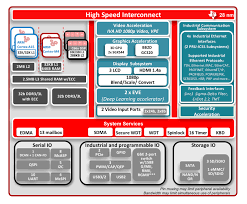
Figura 3. Schema a blocchi del SoC Sitara™ AM5749.
Siti Web correlati:
- Per saperne di più sui Processori Sitara AM57x.
- Scaricate il Kit di sviluppo software per processore (SDK) per processori Sitara AM57x con deep learning per applicazioni embedded.
- Scaricate il Progetto di riferimento per inferenza di deep learning per applicazioni embedded
a cura di Mark Nadeski, Embedded Processing Texas Instruments