Non ci sono prodotti a carrello.
di Christophe Waelchli (Product manager di Onsemi)
Senza i progressi compiuti nella tecnologia di produzione dei semiconduttori negli ultimi decenni e lo sviluppo di architetture sempre più sofisticate, i moderni apparecchi acustici sarebbero ancora una chimera. L’evoluzione dei processori nel tempo è testimoniato dal numero dei circuiti integrati che li compongono. I primi processori per PC (Personal Computer) erano realizzati con decine di migliaia di transistor realizzati utilizzando geometrie dell’ordine di alcuni micron, mentre per i processori odierni si utilizzano decine di miliardi di transistor realizzati sfruttando nodi tecnologici inferiori di un fattore dell’ordine delle migliaia di volte.
I benefici di un livello di integrazione così spinto non sono ovviamente limitati al settore dei PC. L’industria dei semiconduttori nel suo complesso ha accesso a una tecnologia in costante evoluzione, consentendo ai produttori operanti in tutti I mercati verticali di compiere notevoli progressi. Il settore degli apparecchi acustici, in particolare, ha tratto notevoli vantaggi dalle architetture di elaborazione parallele multi-core che permettono di incrementare in maniera esponenziale la capacità di elaborazione, minimizzare i cicli di clock e ridurre in modo sostanziale i consumi di potenza. Core di questo tipo sono in grado di elaborare algoritmi molto sofisticati, come quelli tipici dell’intelligenza artificiale (AI).
Nel caso degli apparecchi acustici elettronici, il primo sviluppo degno di nota è stato il ricorso da parte dei produttori di queste protesi all’amplificazione non lineare basata sulla frequenza. In sintesi questa tecnica prevede l’applicazione dell’amplificazione a ciascuna banda di frequenza in funzione del livello di energia contenuto in ciascuna di esse. In ogni banda di frequenza, i rumori più forti verrebbero attenuati e quelli più deboli amplificati, il che si traduce in un miglioramento della qualità del suono e nella possibilità di personalizzazione per gli utilizzatori di apparecchi acustici. L’amplificazione non lineare richiede una notevole potenza di elaborazione perché possa essere applicata nel più breve tempo possibile riducendo in tal modo la latenza del sistema. Ciò è possibile grazie allo sviluppo di progetti “ad hoc” a livello di sistema che sfruttano le potenzialità di core caratterizzati da un elevato grado di parallelismo e bassissima dissipazione che costituiscono il nucleo centrale di questi apparecchi acustici elettronici.
In linea generale, oltre a consentire un’amplificazione di tipo non lineare efficiente, l’introduzione di processori DSP (Digital Signal Processor) ha permesso ai produttori di apparecchi acustici di aggiungere nuovo funzionalità quali la cancellazione della retroazione, che in precedenza non era possibile, riducendo nel contempo i consumi di potenza del sistema. Il segnale audio può essere ora manipolato secondo nuove modalità utilizzando filtri digitali molto più selettivi in termini delle frequenze – e quindi di tipologie di suoni – che vengono elaborate. La disponibilità di maggiori risorse di memoria on-chip consente inoltre di implementare nuove modalità operative, come a esempio la possibilità di adattare il tipo di elaborazione dei segnali in funzione della sorgente. Gli apparecchi acustici potrebbero adattarsi all’ambiente in cui si trova la persona che li indossa – in mezzo alla folla, a una festa o in uno stadio di grandi dimensioni. Le differenti modalità hanno consentito agli apparecchi acustici di adattarsi all’ambiente e alle condizioni prevalenti, utilizzando algoritmi in grado di cambiare i filtri in tempo reale.
Al giorno d’oggi, gli apparecchi acustici digitali sono ancora realizzati sfruttando questo approccio, ma l’aggiunta della connettività wireless ha permesso di ampliare il loro raggio d’azione. Grazie al fatto che gli apparecchi acustici sono ora in grado di collegarsi in modalità wireless con altri dispositivi, è possibile effettuare lo streaming audio tra di loro e controllare gli apparecchi acustici mediante una app installata sullo smartphone senza costringere l’utente ad armeggiare dietro l’orecchio alla ricerca di pulsanti e controlli del volume presenti sull’apparecchio acustico.
Solitamente viene utilizzata la tecnologia Bluetooth® per collegare l’apparecchio acustico a un dispositivo consumer come un apparecchio televisivo o un telefono cellulare. Una volta connesso a un cellulare, si aprono nuovo possibilità. Mediante una app che gira sul cellulare, l’utente può acquisire un maggior controllo sulle modalità di funzionamento. Con questa combinazione, le protesi acustiche digitali entrano nell’universo di IoT (Internet of Things).
Uno sviluppo più recente, anch’esso reso possibile dal continuo aumento del livello di integrazione, è l’introduzione dell’intelligenza artificiale (AI). Grazie all’utilizzo dell’intelligenza artificiale in un apparecchio acustico, quest’ultimo può reagire e adattarsi in maniera più efficace alle esigenze dell’utilizzatore, alle sue preferenze e alle condizioni prevalenti.
Integrazione sempre più spinta per gli apparecchi acustici della prossima generazione
Uno dei più recenti esempi del ruolo dell’integrazione nel processo di semplificazione dello sviluppo di protesi acustiche, e più in generale di dispositivi hearable (in sintesi auricolari smart che si portano nelle orecchie) di prossima generazione, in grado di supportare l’intelligenza artificiale è rappresentato dal DSP audio di fascia alta EZAIRO® 8300 di onsemi™ (il cui schema a blocchi è riportato in figura 1). Esso integra sei core processore, compreso un processore per reti neurali il cui compito è accelerare le funzionalità dell’intelligenza artificiale. Questo DSP di 6a generazione, realizzato sfruttando le competenze acquisite da onsemi nel progetto di processori audio a livello di sistema, è un dispositivo in grado di fornire una potenza di elaborazione doppia rispetto al suo predecessore Ezairo 7100, a fronte di una diminuzione dei consumi di potenza.
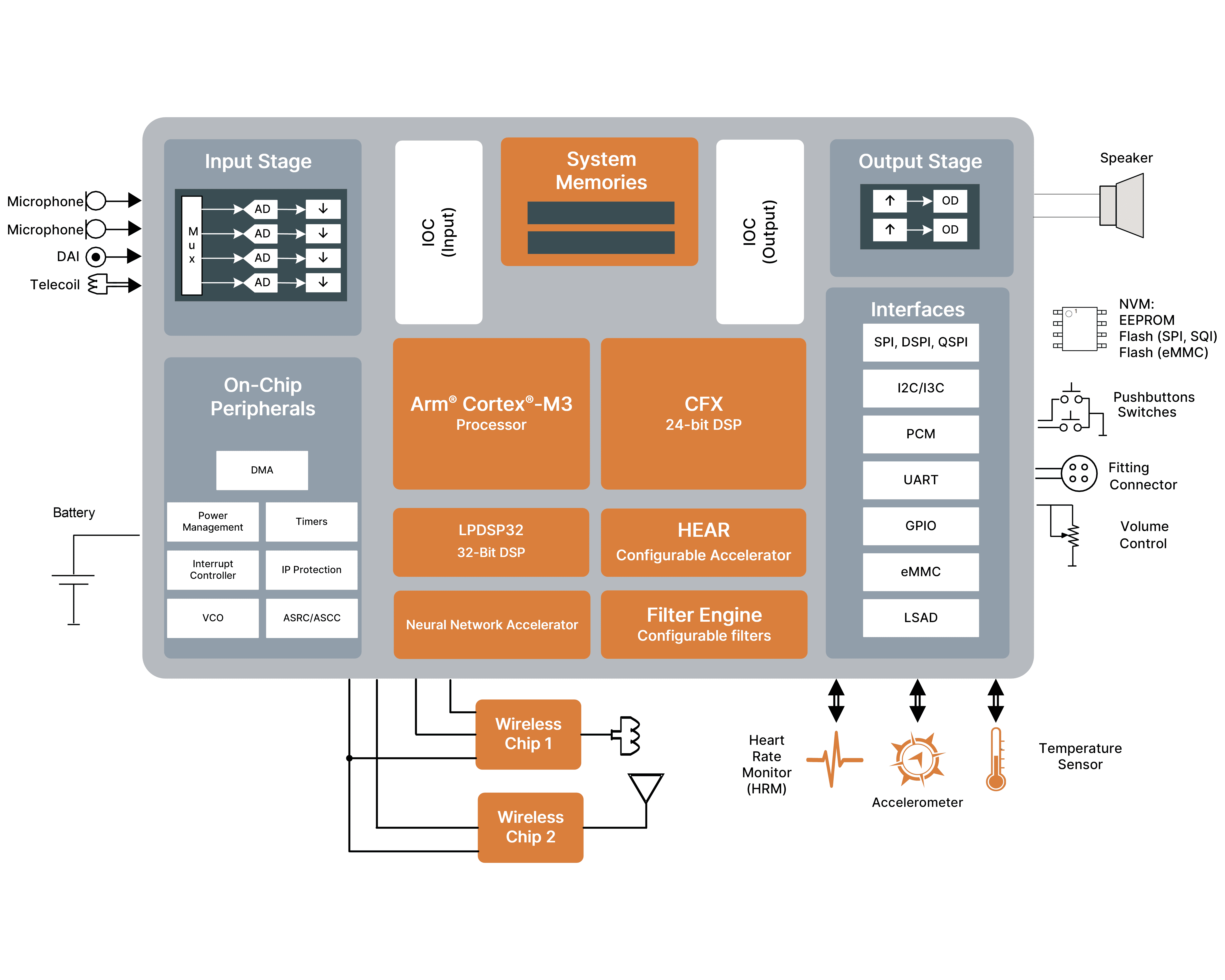
Figura 1 – Schema a blocchi del processore DSP Ezairo 8300 di onsemi
Questo sistema, basato su DSP programmabile e aperto, assicura le più elevate prestazioni in termini di MIPS/mW, consentendo comunque ai produttori di implementare le loro specifiche funzionalità definite via software. Ciò grazie al modo in cui ciascun core processore è stato progettato, che consente di utilizzare il medesimo chip sia nelle protesi acustiche sia nei dispositivi hearable, due categorie di prodotti ciascuna con propri requisiti specifici.
La programmabilità, la caratteristica che è alla base della flessibilità di questa soluzione, è supportata da 6 core di elaborazione. Il DSP CFX è un core a 24 bit in virgola fissa caratterizzato da un’elevata efficienza di ciclo (cycle efficiency) basato su un’architettura dual Harvard e dual MAC. Esso è completato da un core Arm® Cortex®-M3 con un sottosistema. Solitamente, il DSP CFX o il processore Arm Cortex-M3 possono agire come controllore principale per Ezairo 8300.
Accanto a questi due core di tipo general purpose sono previsti quattro ulteriori processori il cui compito è accelerare processi (task) specifici. Tra questi vi è l’acceleratore configurabile HEAR, un engine per l’elaborazione del segnale ottimizzato per supportare algoritmi avanzati quali compressione del range dinamico, elaborazione direzionale, cancellazione della retroazione e riduzione del rumore.
L’engine di filtro programmabile esegue il filtraggio pre e post elaborazione mediante l’implementazione di filtri IIR (Infinite Impulse Response), FIR (Finite Impulse Response) e biquadratici. L’engine di filtraggio è caratterizzato da un percorso del segnale a bassissima latenza per minimizzare i ritardi in applicazioni che implementano la cancellazione attiva del rumore, oppure quando è richiesta la gestione delle occlusioni. Un core ausiliario sempre in architettura dual Harvard, dual MAC a 32 bit in virgola fissa, denominato LPDSP32, è invece destinato a operazioni compute-intensive, ovvero che richiedono importanti risorse di calcolo.
L’acceleratore di reti neurali (NNA – Neural Network Accelerator), anch’esso configurabile, è dedicato al supporto dell’implementazione di reti neurali sul SoC (System on Chip). L’elaborazione alla periferie della rete (edge computing) è adottata in misura sempre maggiore da tutti i produttori che vogliono sfruttare le potenzialità intrinseche dell’intelligenza artificiale senza incorrere nella penalizzazioni, in termini di latenza e consumi, legate al trasferimento dell’intero processo di elaborazione alle piattaforme cloud. Questo acceleratore NNA contiene 16 blocchi MAC (Multiply/Accumulate) con registri dei coefficienti e degli ingressi e supporta per la compressione/decompressione dei coefficienti e il processo di pruning (o potatura, ovvero il taglio delle connessioni meno rilevanti).
Tutti questi core di elaborazione, compreso l’acceleratore NNA, sono supportate da librerie software per fornire ai produttori i tool necessari per lo sviluppo delle loro protesi acustiche digitali di prossima generazione.
Il SoC può implementare la modifica della velocità di clock (clock scaling) e della tensione (voltage scaling) per ridurre il consumo di potenza quanto non è richiesta l’intera potenza di calcolo, contribuendo in tal modo all’aumento della durata della batteria. Tra le caratteristiche salienti del sistema audio ad alta fedeltà integrato nel DSP audio Ezairo 8300 da segnalare il range dinamico di 108 dB e la frequenza di campionamento fino a 64 kHz. La memoria, di capacità pari a 1,4 MB, ha dimensioni sufficienti per far girare un’applicazione completa e sofisticata tipica di protesi acustiche avanzate in grado di eseguire l’elaborazione audio, migliorare la percezione uditiva e gestire attività biometriche senza richiedere un supporto esterno. Questa memoria è disponibile come risorsa condivisa tra tutti i core di elaborazione. Sono altresì previste funzioni di sicurezza, grazie alle quali il software embedded dei costruttori viene crittografato quando archiviato in una memoria esterna.
Numerosa la dotazione di interfacce, tra cui due interfacce PCM, tre I2C, due I3C, due SPI, una UART, una eMMC e fino a 36 GPIO, oltre a otto ingressi per i convertitori A/D a bassa velocità presenti on chip. Il bus I3C è basato sulle specifiche Improved Inter-IC (I3 appunto) sviluppate dal consorzio MIPI Alliance e concepito per semplificare il progetto e l’integrazione di sensori nei prodotti mobili che sfruttano connessioni wireless. Il percorso audio supporta frequenze di campionamento e range dinamico più elevato, con uno stadio di ingresso configurabile capace di supportare fino a quattro microfoni e uno stadio di uscita in grado di gestire due altoparlanti.
Nuove opportunità per i dispositivi “hearable”
Oltre che per gli apparecchi acustici digitali, il DSP audio Ezairo 8300 può venire impiegato per un categoria emergente di prodotti che viene indicata con il nome di “hearable”. Essa include gli apparecchi acustici che possono essere acquistati senza prescrizione medica (prodotti da banco) e gli auricolari. La differenza tra queste tipologie di dispositivi è divenuta via via sempre più evanescente, in quanto gli apparecchi acustici ora integrano numerose funzionalità a valore aggiunto come a esempio lo streaming audio da dispositivi personali come smartphone e tablet.
Grazie ai dispositivi hearable le opportunità per aggiungere nuove funzionalità sono aumentate sensibilmente: ad esempio è possibile integrare servizi di traduzione dal vivo, di dettatura e di navigazione, In effetti, tutto ciò che può essere trasmesso in modo udibile (via voce) attraverso un cellulare può essere inviato mediante dispositivi harable. Nel momento in cui diventa possibile integrare altre tecnologie, come i sensori di movimento MEMS, in questi dispositivi indossabili, è verosimile che il modello di interfaccia utente venga completamente ridefinito.
Considerazioni conclusive
La tecnologia degli apparecchi acustici è in continua evoluzione, guidata in parte dagli sviluppi nella tecnologia di produzione dei semiconduttori, ma anche da nuove architetture di sistema che consentono di fare di più consumando la stessa energia. Adottando un processo avanzato a 22 nm per Ezairo 8300, ON Semiconductor ha prodotto un SoC avanzato in grado di alimentare la prossima generazione di apparecchi acustici e dispositivi acustici avanzati.
La tecnologia degli apparecchi acustiti è in continua evoluzione grazie sia agli sviluppi nel campo della produzione dei semiconduttori sia all’introduzione di nuove architetture che permettono di supportare un numero maggiore di funzioni a parità di consumi di potenza. Con l’introduzione di Ezairo 8300, realizzato con un avanzato processo da 22 nm, onsemi ha messo a disposizione un SoC avanzato in grado di soddisfare al meglio le esigenze degli avanzati dispositivi hearable e delle protesi acustiche della prossima generazione.